Beautiful Soup과 Python 3으로 웹 페이지를 긁는 방법
소개
많은 데이터 분석, 빅 데이터 및 기계 학습 프로젝트에서는 작업할 데이터를 수집하기 위해 웹 사이트를 스크래핑해야 합니다. Python 프로그래밍 언어는 데이터 과학 커뮤니티에서 널리 사용되므로 자체 프로젝트에서 사용할 수 있는 모듈 및 도구의 생태계가 있습니다. 이 튜토리얼에서는 Beautiful Soup 모듈에 초점을 맞출 것입니다.
태그 수프 및 기타 잘못된 마크업).
이 자습서에서는 텍스트 데이터를 가져오고 수집한 정보를 CSV 파일에 쓰기 위해 웹 페이지를 수집하고 구문 분석합니다.
전제 조건
이 튜토리얼을 진행하기 전에 컴퓨터에 서버 기반 Python 프로그래밍 환경이 설정되어 있어야 합니다.
Requests 및 Beautiful Soup 모듈이 설치되어 있어야 합니다. \How To Work with Web Data Using Requests and Beautiful Soup with Python 3\ 자습서를 따라 달성할 수 있습니다. 또한 이러한 모듈에 대해 잘 알고 있으면 유용합니다.
또한 웹에서 스크랩한 데이터로 작업할 것이므로 HTML 구조와 태깅에 익숙해야 합니다.
데이터 이해
이 튜토리얼에서는 미국 국립 미술관 공식 웹사이트의 데이터를 사용하여 작업합니다. 내셔널 갤러리는 워싱턴 D.C.의 내셔널 몰에 위치한 미술관입니다. 르네상스 시대부터 현재까지 13,000명 이상의 예술가가 제작한 120,000점 이상의 작품을 소장하고 있습니다.
이 튜토리얼을 업데이트할 때 다음 URL의 Wayback Machine을 통해 사용할 수 있는 아티스트 인덱스를 검색하고 싶습니다.
참고: 위의 긴 URL은 이 웹사이트가 Internet Archive에 의해 보관되었기 때문입니다.
인터넷 아카이브는 인터넷 사이트 및 기타 디지털 미디어에 대한 무료 액세스를 제공하는 비영리 디지털 라이브러리입니다. 이 조직은 사이트의 기록을 보존하기 위해 웹 사이트의 스냅샷을 찍고 현재 이 자습서가 처음 작성되었을 때 사용 가능한 이전 버전의 내셔널 갤러리 사이트에 액세스할 수 있습니다. Internet Archive는 동일한 사이트와 사용 가능한 데이터의 반복 비교를 포함하여 모든 종류의 기록 데이터 스크랩을 수행할 때 염두에 두어야 할 좋은 도구입니다.
Internet Archive의 헤더 아래에 다음과 같은 페이지가 표시됩니다.
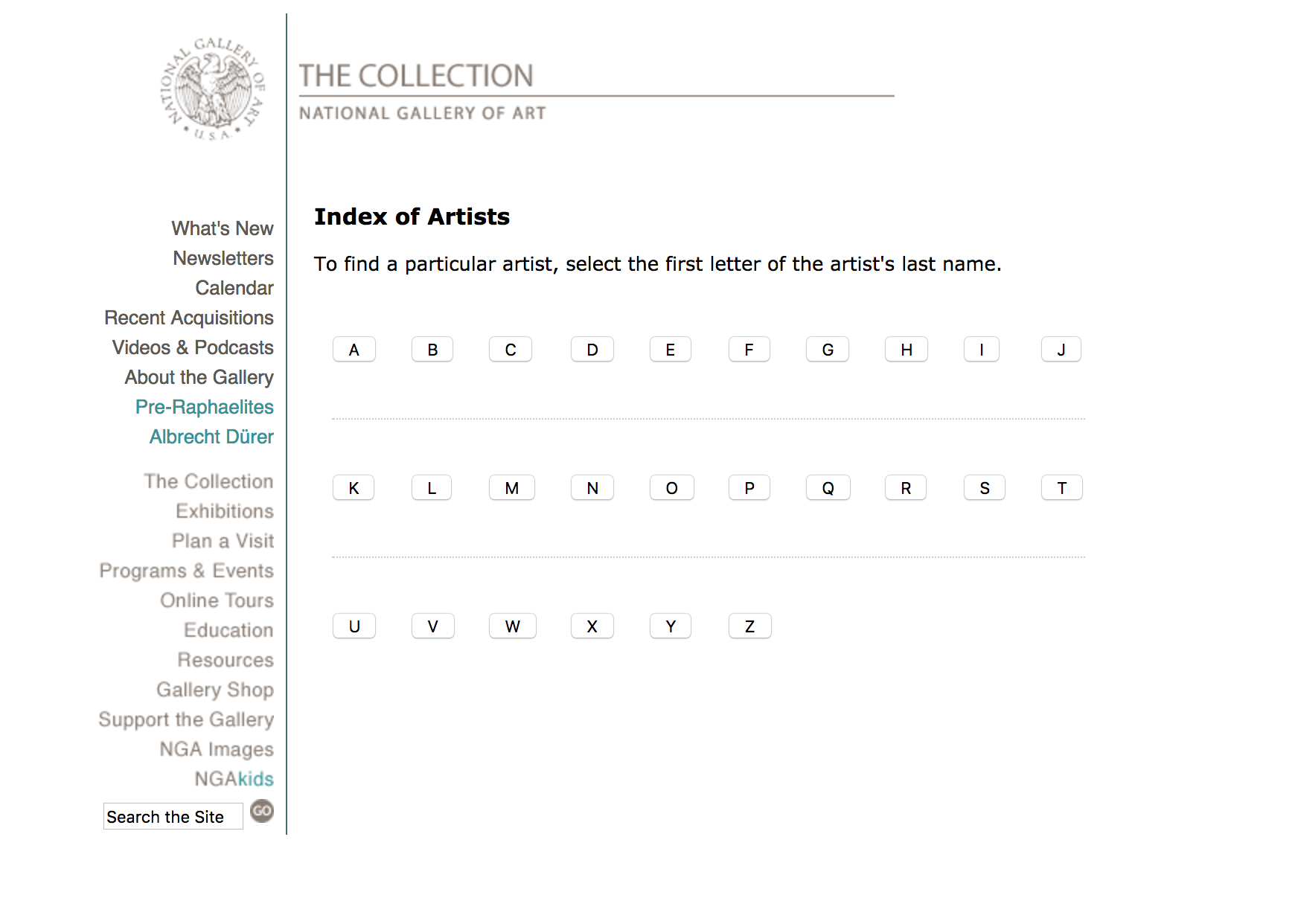
Beautiful Soup으로 웹 스크래핑에 대해 배우기 위해 이 프로젝트를 수행할 것이므로 사이트에서 너무 많은 데이터를 가져올 필요가 없으므로 스크랩하려는 아티스트 데이터의 범위를 제한합시다. 따라서 하나의 문자를 선택하겠습니다. 이 예에서는 문자 Z를 선택합니다. 그러면 다음과 같은 페이지가 표시됩니다.

위의 페이지에서 작성 시점에 나열된 첫 번째 아티스트는 Niccola의 Zabaglia라는 것을 알 수 있습니다. 문자 Z에 대한 다음 URL을 사용하여 이 첫 번째 페이지 작업을 시작합니다.
나중에 나열하기 위해 선택한 편지의 총 페이지 수를 기록하는 것이 중요합니다. 아티스트의 마지막 페이지를 클릭하면 찾을 수 있습니다. 이 경우 총 4페이지이며, 작성 시점에 마지막으로 나열된 아티스트는 Zykmund, Václav입니다. Z 아티스트의 마지막 페이지 URL은 다음과 같습니다.
그러나 첫 번째 페이지의 동일한 Internet Archive 숫자 문자열을 사용하여 위 페이지에 액세스할 수도 있습니다.
이 자습서의 뒷부분에서 이러한 페이지를 반복할 것이기 때문에 이는 중요합니다.
이 웹 페이지 설정 방법에 익숙해지려면 개발자 도구를 살펴보십시오.
라이브러리 가져오기
코딩 프로젝트를 시작하기 위해 Python 3 프로그래밍 환경을 활성화해 보겠습니다. 환경이 있는 디렉터리에 있는지 확인하고 다음 명령을 실행합니다.
- . my_env/bin/activate
프로그래밍 환경이 활성화되면 예를 들어 nano를 사용하여 새 파일을 만듭니다. 원하는 대로 파일 이름을 지정할 수 있으며 이 자습서에서는 nga_z_artists.py라고 합니다.
- nano nga_z_artists.py
이 파일 내에서 사용할 라이브러리인 Requests 및 Beautiful Soup 가져오기를 시작할 수 있습니다.
Requests 라이브러리를 사용하면 Python 프로그램 내에서 사람이 읽을 수 있는 방식으로 HTTP를 사용할 수 있으며 Beautiful Soup 모듈은 웹 스크래핑을 빠르게 완료하도록 설계되었습니다.
import 문을 사용하여 Request와 Beautiful Soup을 모두 가져옵니다. Beautiful Soup의 경우 Beautiful Soup 4가 있는 패키지인 bs4에서 가져올 것입니다.
# Import libraries
import requests
from bs4 import BeautifulSoup
Requests 및 Beautiful Soup 모듈을 모두 가져오면 먼저 페이지를 수집한 다음 파싱하는 작업으로 넘어갈 수 있습니다.
웹 페이지 수집 및 구문 분석
다음 단계는 요청이 있는 첫 번째 웹 페이지의 URL을 수집하는 것입니다. 첫 번째 페이지의 URL을 requests.get() 메서드에 할당합니다.
import requests
from bs4 import BeautifulSoup
# Collect first page of artists’ list
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
<$>[참고]
이제 BeautifulSoup 객체 또는 구문 분석 트리를 생성합니다. 이 개체는 Requests(서버의 응답 내용)에서 page.text 문서를 인수로 취한 다음 Python의 내장 html.parser에서 구문 분석합니다.
import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
# Create a BeautifulSoup object
soup = BeautifulSoup(page.text, 'html.parser')
페이지를 수집, 파싱 및 BeautifulSoup 개체로 설정하면 원하는 데이터 수집으로 넘어갈 수 있습니다.
웹 페이지에서 텍스트 가져오기
이 프로젝트를 위해 웹사이트에서 사용할 수 있는 아티스트 이름과 관련 링크를 수집합니다. 아티스트의 국적 및 날짜와 같은 다른 데이터를 수집할 수 있습니다. 수집하려는 데이터가 무엇이든 웹 페이지의 DOM에서 데이터를 설명하는 방법을 찾아야 합니다.
이렇게 하려면 웹 브라우저에서 첫 번째 아티스트의 이름인 Zabaglia, Niccola를 마우스 오른쪽 버튼으로 클릭(또는 macOS에서 CTRL + 클릭)합니다. 팝업되는 상황에 맞는 메뉴 내에서 Inspect Element(Firefox) 또는 Inspect(Chrome)와 유사한 메뉴 항목을 볼 수 있습니다.
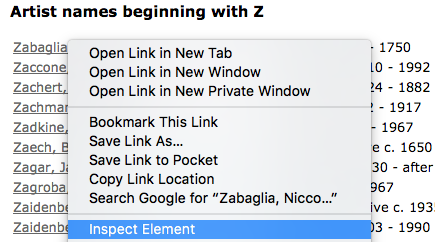
관련 검사 메뉴 항목을 클릭하면 웹 개발자용 도구가 브라우저에 나타납니다. 이 목록에서 아티스트 이름과 연결된 클래스 및 태그를 찾고자 합니다.
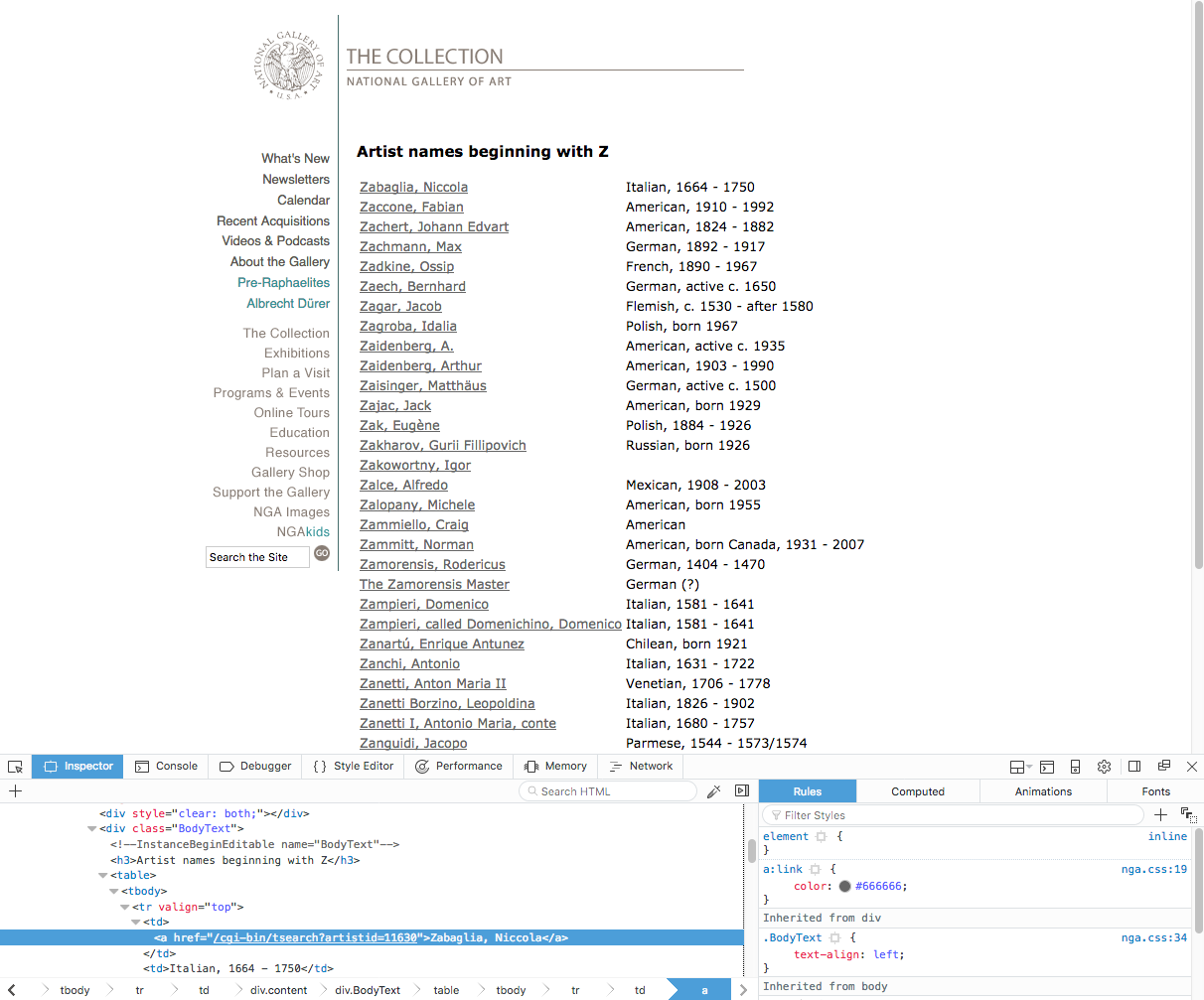
먼저 이름 테이블이 class=BodyText인 <div> 태그 내에 있음을 볼 수 있습니다. 이는 웹 페이지의 이 섹션 내에서 텍스트만 검색하도록 하기 위해 중요합니다. 또한 Zabaglia, Niccola라는 이름이 아티스트를 설명하는 웹 페이지를 참조하기 때문에 링크 태그에 있음을 알 수 있습니다. 따라서 링크에 대한 <a> 태그를 참조하려고 합니다. 각 아티스트의 이름은 링크에 대한 참조입니다.
이를 위해 Beautiful Soup의 다음으로 프로그램 파일의 맨 아래에 Beautiful Soup 구문 분석 트리를 멋진 형식의 유니코드 문자열로 바꾸기 위해 지금까지 프로그램을 실행해 보겠습니다. 이렇게 하면 다음과 같은 결과가 표시됩니다. 이 시점에서 출력에서 볼 수 있는 것은 지금까지 웹 페이지의 한 페이지의 하단 링크를 제거하기 위해 다시 마우스 오른쪽 버튼을 클릭하고 DOM을 검사합니다. 따라서 Beautiful Soup을 사용하여 변수 이제 이 시점에서 출력에 더 이상 웹 페이지 하단의 링크가 포함되지 않고 이제 아티스트 이름과 연결된 링크만 표시됩니다. 지금까지 아티스트 이름이 있는 링크를 구체적으로 타겟팅했지만 실제로 원하지 않는 추가 태그 데이터가 있습니다. 다음 섹션에서 제거해 보겠습니다. 실제 아티스트의 이름에만 액세스하려면 전체 링크 태그를 인쇄하는 대신 Beautiful Soup의 각 항목의 인덱스 번호를 호출하여 위의 목록을 반복하고 있음에 유의하십시오. 우리는 문자 Z의 첫 페이지에 있는 모든 아티스트 이름 목록을 돌려받았습니다. 하지만 해당 아티스트와 연결된 URL도 캡처하려면 어떻게 해야 할까요? Beautiful Soup의 위 링크의 출력에서 전체 URL이 캡처되지 않는다는 것을 알고 있으므로 링크 문자열을 URL 문자열의 앞 부분과 연결합니다(이 경우 다음 줄도 위의 프로그램을 실행하면 아티스트 이름과 아티스트에 대해 자세히 알려주는 링크의 URL이 모두 수신됩니다. 지금은 웹사이트에서 정보를 받고 있지만 현재는 터미널 창에 인쇄하는 중입니다. 대신 이 데이터를 캡처하여 파일에 작성하여 다른 곳에서 사용할 수 있도록 합시다. 터미널 창에만 있는 데이터를 수집하는 것은 그다지 유용하지 않습니다. 쉼표로 구분된 값(CSV) 파일을 사용하면 테이블 형식 데이터를 일반 텍스트로 저장할 수 있으며 스프레드시트 및 데이터베이스의 일반적인 형식입니다. 이 섹션을 시작하기 전에 Python에서 일반 텍스트 파일을 처리하는 방법에 익숙해져야 합니다. 먼저 Python 프로그래밍 파일의 맨 위에 있는 다른 모듈과 함께 Python의 내장 다음으로 쓸 마지막으로 아래 파일에서 이러한 각 작업에 대한 행을 볼 수 있습니다. 지금 여는 데 사용하는 항목에 따라 다음과 같이 표시될 수 있습니다. 또는 스프레드시트처럼 보일 수도 있습니다. 두 경우 모두 이제 수집한 정보가 컴퓨터의 메모리에 저장되므로 이 파일을 사용하여 보다 의미 있는 방식으로 데이터 작업을 할 수 있습니다. 우리는 성이 Z로 시작하는 아티스트 목록의 첫 번째 페이지에서 데이터를 가져오는 프로그램을 만들었습니다. 그러나 웹사이트에는 이러한 아티스트의 총 4페이지가 있습니다. 이러한 모든 페이지를 수집하기 위해 시작하려면 페이지를 보유할 목록을 초기화해야 합니다. 이 초기화된 목록을 다음 이 튜토리얼의 앞부분에서 문자 Z(또는 사용 중인 문자)로 시작하는 아티스트 이름이 포함된 총 페이지 수에 주의를 기울여야 한다고 언급했습니다. 문자 Z에 대한 페이지가 4개이므로 위의 이 특정 웹 사이트의 경우 URL은 이 루프 외에도 위의 각 페이지를 통과하는 두 번째 루프가 있습니다. 이 두 개의 위의 코드에서 첫 번째 이 두 개의 프로그래밍 파일의 더 큰 컨텍스트 내에서 전체 코드는 다음과 같습니다. 이 프로그램은 약간의 작업을 수행하므로 CSV 파일을 만드는 데 약간의 시간이 걸립니다. 작업이 완료되면 아티스트의 이름과 Zabaglia, Niccola에서 Zykmund, Václav까지의 관련 링크를 보여주는 출력이 완료됩니다. 웹 페이지를 스크랩할 때 정보를 가져오는 서버를 고려하는 것이 중요합니다. 사이트에 웹 스크래핑과 관련된 서비스 약관 또는 사용 약관이 있는지 확인하십시오. 또한 사이트에 직접 스크랩하기 전에 데이터를 가져올 수 있는 API가 있는지 확인하세요. 데이터 수집을 위해 지속적으로 서버에 접속하지 마십시오. 사이트에서 필요한 것을 수집한 후에는 다른 사람의 서버에 부담을 주지 않고 로컬에서 데이터를 검토하는 스크립트를 실행하십시오. 또한 웹 사이트에서 귀하를 식별하고 질문이 있는 경우 후속 조치를 취할 수 있도록 귀하의 이름과 이메일이 포함된 헤더를 스크랩하는 것이 좋습니다. Python 요청 라이브러리와 함께 사용할 수 있는 헤더의 예는 다음과 같습니다. 식별 가능한 정보가 포함된 헤더를 사용하면 서버 로그를 검토하는 사람들이 귀하에게 연락할 수 있습니다. 이 튜토리얼은 Python과 Beautiful Soup을 사용하여 웹 사이트에서 데이터를 스크랩했습니다. 수집한 텍스트를 CSV 파일에 저장했습니다. 더 많은 데이터를 수집하고 CSV 파일을 더 강력하게 만들어 이 프로젝트에서 계속 작업할 수 있습니다. 예를 들어 각 아티스트의 국적과 연도를 포함할 수 있습니다. 배운 내용을 사용하여 다른 웹사이트에서 데이터를 스크랩할 수도 있습니다. 웹에서 정보를 가져오는 방법에 대해 계속 알아보려면 \Scrapy 및 Python 3으로 웹 페이지를 크롤링하는 방법\ 자습서를 읽으십시오.find() 및 find_all() 메서드를 사용하여 BodyText<에서 아티스트 이름의 텍스트를 가져옵니다. /코드> <코드>import requests
from bs4 import BeautifulSoup
# Collect and parse first page
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Pull all text from the BodyText div
artist_name_list = soup.find(class_='BodyText')
# Pull text from all instances of <a> tag within BodyText div
artist_name_list_items = artist_name_list.find_all('a')
artist_name_list_items 변수에 입력한 모든 아티스트 이름을 반복하기 위해 for 루프를 만들고자 합니다.prettify() 메서드로 이 이름을 인쇄합니다....
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Create for loop to print out all artists' names
for artist_name in artist_name_list_items:
print(artist_name.prettify())
불필요한 데이터 제거
<div> 섹션 내에서 모든 링크 텍스트 데이터를 수집할 수 있었습니다. 그러나 아티스트 이름을 참조하지 않는 하단 링크는 원하지 않으므로 해당 부분을 제거하도록 노력하겠습니다. :
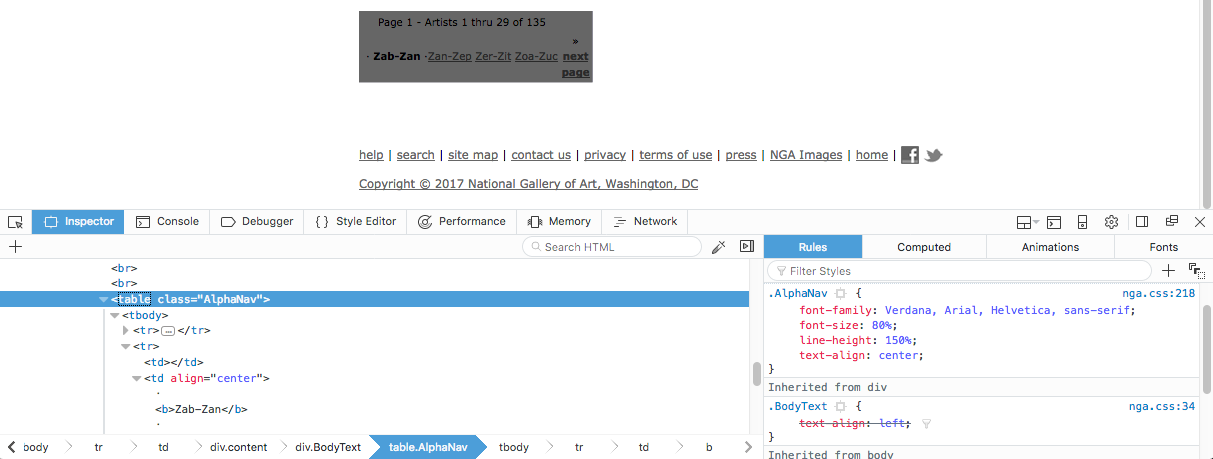
AlphaNav 클래스를 찾고 decompose() 메서드를 사용하여 구문 분석 트리에서 태그를 제거한 다음 내용과 함께 제거할 수 있습니다.last_links를 사용하여 이러한 하단 링크를 참조하고 프로그램 파일에 추가합니다.import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
# Remove bottom links
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
print(artist_name.prettify())
python nga_z_artist.py 명령으로 프로그램을 실행하면 다음과 같은 결과가 표시됩니다.태그에서 콘텐츠 가져오기
<a> 태그의 내용을 대상으로 지정해야 합니다..contents로 이 작업을 수행할 수 있습니다. 태그의 자식을 Python 목록 데이터 유형으로 반환합니다.for 루프를 수정하여 전체 링크와 태그를 인쇄하는 대신 하위 목록(예: 아티스트의 전체 이름)을 인쇄하도록 합시다.import requests
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
# Use .contents to pull out the <a> tag’s children
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
print(names)
python 명령으로 프로그램을 실행하여 다음 출력을 볼 수 있습니다.get(href) 메소드를 사용하여 페이지의 <a> 태그 내에서 찾은 URL을 추출할 수 있습니다.https://web.archive.org/ ).for 루프에 추가합니다....
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
print(names)
print(links)
CSV 파일에 데이터 쓰기
csv 모듈을 가져와야 합니다.import csv
z-artist-names.csv라는 파일을 만들고 엽니다(변수 f for file here) w 모드를 사용합니다. 또한 writerow() 메서드에 목록으로 전달할 Name 및 Link와 같은 맨 위 행 제목을 작성합니다.f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
for 루프 내에서 아티스트의 이름 및 관련 링크로 각 행을 작성합니다.f.writerow([names, links])
import requests
import csv
from bs4 import BeautifulSoup
page = requests.get('https://web.archive.org/web/20121007172955/http://www.nga.gov/collection/anZ1.htm')
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
# Create a file to write to, add headers row
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
# Add each artist’s name and associated link to a row
f.writerow([names, links])
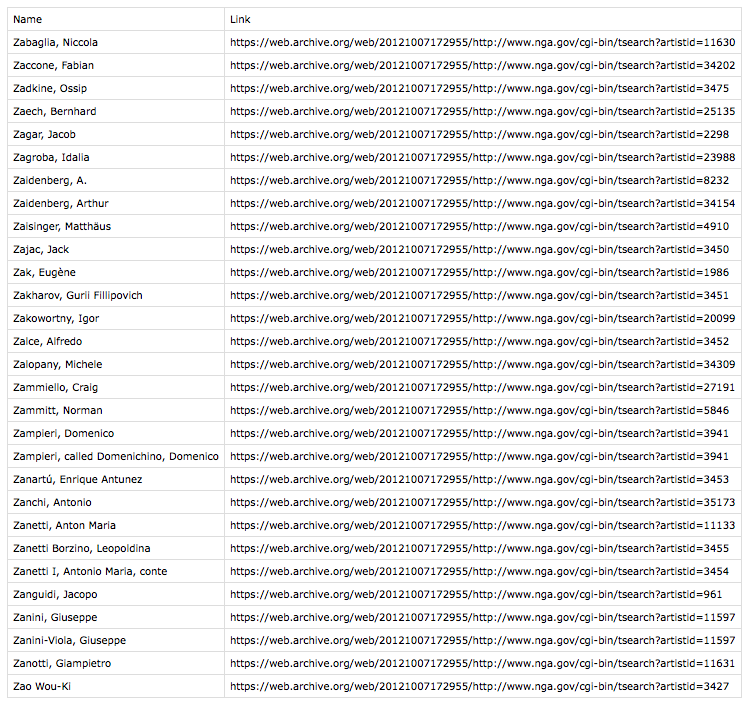
python 명령으로 프로그램을 실행하면 터미널 창에 출력이 반환되지 않습니다. 대신 작업 중인 디렉토리에 z-artist-names.csv라는 파일이 생성됩니다.Name,Link
"Zabaglia, Niccola",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=11630
"Zaccone, Fabian",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=34202
"Zadkine, Ossip",https://web.archive.org/web/20121007172955/http://www.nga.gov/cgi-bin/tsearch?artistid=3475w
...
관련 페이지 검색
for 루프를 사용하여 더 많은 반복을 수행할 수 있습니다. 이것은 우리가 지금까지 작성한 대부분의 코드를 수정하지만 유사한 개념을 사용할 것입니다.pages = []
for 루프로 채웁니다.for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
1에서 5 범위로 for 루프를 구성하여 4페이지 각각.https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ 문자열로 시작하고 그 뒤를 따릅니다. 페이지 번호(문자열로 변환하는 for 루프의 정수 i가 됨)와 함께 .htm로 끝납니다. . 이 문자열을 함께 연결한 다음 결과를 pages 목록에 추가합니다.for 루프의 코드는 총 4페이지 각각에 대해 Z 아티스트의 첫 번째 페이지에 대해 완료한 작업을 수행하므로 지금까지 생성한 코드와 유사합니다. 원래 프로그램을 두 번째 for 루프에 넣었기 때문에 이제 원래 루프가 중첩된 for 루프에 포함되어 있습니다.for 루프는 다음과 같습니다.pages = []
for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
f.writerow([names, links])
for 루프가 페이지를 반복하고 두 번째 for 루프가 각 페이지에서 데이터를 스크랩한 다음 아티스트의 이름과 링크는 각 페이지의 각 행에 한 줄씩 표시됩니다.for 루프는 import 문, CSV 파일 생성 및 작성기(파일의 헤더를 쓰기 위한 라인 포함) 및 import requests
import csv
from bs4 import BeautifulSoup
f = csv.writer(open('z-artist-names.csv', 'w'))
f.writerow(['Name', 'Link'])
pages = []
for i in range(1, 5):
url = 'https://web.archive.org/web/20121007172955/https://www.nga.gov/collection/anZ' + str(i) + '.htm'
pages.append(url)
for item in pages:
page = requests.get(item)
soup = BeautifulSoup(page.text, 'html.parser')
last_links = soup.find(class_='AlphaNav')
last_links.decompose()
artist_name_list = soup.find(class_='BodyText')
artist_name_list_items = artist_name_list.find_all('a')
for artist_name in artist_name_list_items:
names = artist_name.contents[0]
links = 'https://web.archive.org' + artist_name.get('href')
f.writerow([names, links])
배려심
import requests
headers = {
'User-Agent': 'Your Name, example.com',
'From': 'email@example.com'
}
url = 'https://example.com'
page = requests.get(url, headers = headers)
결론