EDA - 탐색적 데이터 분석: Python 함수 사용
이전 기사에서는 그래픽 방법을 사용하여 EDA를 수행하는 방법을 살펴보았습니다. 이 기사에서는 Python에서 탐색적 데이터 분석에 사용되는 Python 함수에 중점을 둘 것입니다. 우리 모두 알고 있듯이 EDA가 얼마나 중요한지 데이터에 대한 간략한 이해를 제공합니다. 그래서 많은 시간을 낭비하지 않고 굴러 갑시다!
탐색적 데이터 분석 - EDA
- 데이터를 조사하고 핵심 통찰력을 요약하기 위해 EDA가 적용됩니다.
- 데이터, 분포, null 값 등에 대한 기본적인 이해를 제공합니다.
- 그래프를 사용하거나 Python 함수를 통해 데이터를 탐색할 수 있습니다.
- 두 가지 유형의 분석이 있습니다. 단변량 및 이변량. 단변량에서는 단일 속성을 분석하게 됩니다. 그러나 이변량에서는 대상 속성이 있는 속성을 분석하게 됩니다.
- 비그래픽 접근 방식에서는 모양, 요약, 설명, isnull, 정보, 데이터 유형 등과 같은 기능을 사용하게 됩니다.
- 그래픽 접근 방식에서는 산점도, 상자, 막대, 밀도 및 상관관계 도표와 같은 도표를 사용하게 됩니다.
데이터 로드
글쎄, 먼저 먼저. EDA를 수행하기 위해 타이타닉 데이터 세트를 Python에 로드합니다.
#Load the required libraries
import pandas as pd
import numpy as np
import seaborn as sns
#Load the data
df = pd.read_csv('titanic.csv')
#View the data
df.head()
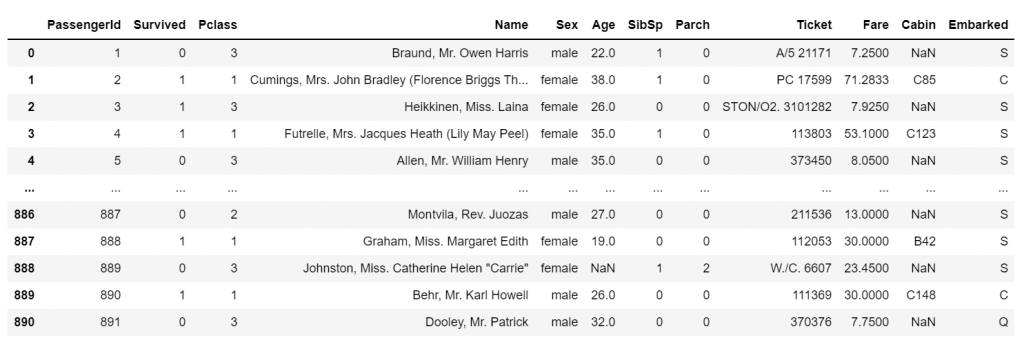
데이터를 탐색할 준비가 되었습니다!
1. 데이터 기본 정보 - EDA
df.info() 함수는 데이터 세트에 대한 기본 정보를 제공합니다. 모든 데이터는 해당 정보를 아는 것부터 시작하는 것이 좋습니다. 데이터와 어떻게 작동하는지 봅시다.
#Basic information
df.info()
#Describe the data
df.describe()

- 데이터 설명 - 기술 통계.

이 함수를 사용하면 기술 통계와 함께 위의 출력에 표시된 대로 null 값, 데이터 유형 및 메모리 사용량을 볼 수 있습니다.
2. 중복 값
존재하는 중복 값의 합계에 df.duplicate.sum() 함수를 사용할 수 있습니다. 데이터에 중복 값이 있는 경우 중복 값의 수를 표시합니다.
#Find the duplicates
df.duplicated().sum()
음, 함수는 '0'을 반환했습니다. 즉, 데이터 세트에 하나의 중복 값이 없으며 알아두면 매우 좋습니다.
3. 데이터의 고유한 값
Python의 unique() 함수를 사용하여 특정 열에서 고유한 값의 수를 찾을 수 있습니다.
#unique values
df['Pclass'].unique()
df['Survived'].unique()
df['Sex'].unique()
array([3, 1, 2], dtype=int64)
array([0, 1], dtype=int64)
array(['male', 'female'], dtype=object)
unique() 함수는 데이터에 있는 고유한 값을 반환했으며 꽤 멋집니다!
4. 고유 개수 시각화
예, 데이터에 있는 고유한 값을 시각화할 수 있습니다. 이를 위해 seaborn 라이브러리를 사용할 것입니다. sns.countlot() 함수를 호출하고 카운트 도표를 그릴 변수를 지정해야 합니다.
#Plot the unique values
sns.countplot(df['Pclass']).unique()

대단해! 당신은 잘하고 있습니다. 그만큼 간단합니다. EDA에는 두 가지 접근 방식이 있지만 그래픽과 비그래픽의 혼합을 통해 더 큰 그림을 볼 수 있습니다.
5. Null 값 찾기
null 값을 찾는 것은 EDA에서 가장 중요한 단계입니다. 내가 여러 번 말했듯이 데이터의 품질을 보장하는 것이 가장 중요합니다. 그럼 null 값을 찾는 방법을 알아보겠습니다.
#Find null values
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 177
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 687
Embarked 2
dtype: int64
아뇨, 'Age' 및 'Cabin' 변수에 일부 null 값이 있습니다. 그러나 걱정하지 마십시오. 우리는 곧 그들을 처리할 방법을 찾을 것입니다.
6. Null 값 바꾸기
모든 null 값을 특정 데이터로 바꾸는 replace() 함수가 있습니다. 너무 좋다!
#Replace null values
df.replace(np.nan,'0',inplace = True)
#Check the changes now
df.isnull().sum()
PassengerId 0
Survived 0
Pclass 0
Name 0
Sex 0
Age 0
SibSp 0
Parch 0
Ticket 0
Fare 0
Cabin 0
Embarked 0
dtype: int64
우! 굉장하다. 그림과 같이 데이터에서 null 값을 찾고 바꾸는 것은 매우 쉽습니다. null 값을 대체하기 위해 0을 사용했습니다. 평균 또는 중앙값과 같은 보다 의미 있는 방법을 선택할 수도 있습니다.
7. 데이터 유형 알기
탐색 중인 데이터 유형을 아는 것은 매우 중요하고 쉬운 프로세스이기도 합니다. 어떻게 작동하는지 봅시다.
#Datatypes
df.dtypes
PassengerId int64
Survived int64
Pclass int64
Name object
Sex object
Age object
SibSp int64
Parch int64
Ticket object
Fare float64
Cabin object
Embarked object
dtype: object
그게 다야. 이 표시에 대해 dtypes 함수를 사용해야 하며 각 속성의 데이터 유형을 얻을 수 있습니다.
8. 데이터 필터링
예, 일부 논리를 기반으로 데이터를 필터링할 수 있습니다.
#Filter data
df[df['Pclass']==1].head()

위의 코드는 클래스 1에 속하는 데이터 값만 반환한 것을 확인할 수 있습니다.
9. 빠른 박스 플롯
한 줄의 코드를 사용하여 숫자 열에 대한 상자 그림을 만들 수 있습니다.
#Boxplot
df[['Fare']].boxplot()
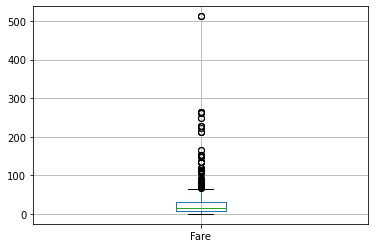
10. 상관관계 도표 - EDA
마지막으로 변수 간의 상관 관계를 찾기 위해 상관 함수를 사용할 수 있습니다. 이렇게 하면 서로 다른 변수 간의 상관 관계 강도에 대한 공정한 아이디어를 얻을 수 있습니다.
#Correlation
df.corr()

이것은 +1에서 -1 사이의 상관관계 매트릭스입니다. 여기서 +1은 양의 상관관계가 높고 -1은 음의 상관관계가 높습니다.
아래와 같이 seaborn 라이브러리를 사용하여 상관관계 매트릭스를 시각화할 수도 있습니다.
#Correlation plot
sns.heatmap(df.corr())

엔딩 노트 - EDA
EDA는 모든 분석에서 가장 중요한 부분입니다. 데이터에 대해 많은 것을 알게 될 것입니다. EDA에서 대부분의 질문에 대한 답변을 찾을 수 있습니다. 시각화로 데이터를 탐색하는 데 사용되는 대부분의 파이썬 함수를 보여주려고 노력했습니다. 이 기사에서 뭔가를 얻었기를 바랍니다.
지금은 여기까지입니다! 행복한 파이썬 :)
더 읽기: 탐색적 데이터 분석