Python 3에서 ARIMA를 사용한 시계열 예측 가이드
소개
시계열은 미래 가치를 예측할 수 있는 기회를 제공합니다. 이전 값을 기반으로 시계열을 사용하여 몇 가지 예를 들면 경제, 날씨 및 용량 계획의 추세를 예측할 수 있습니다. 시계열 데이터의 특정 속성은 일반적으로 특수한 통계 방법이 필요함을 의미합니다.
이 자습서에서는 신뢰할 수 있는 시계열 예측을 생성하는 것을 목표로 합니다. 자기상관, 정상성, 계절성의 개념을 소개하고 논의하는 것으로 시작하여 ARIMA로 알려진 시계열 예측에 가장 일반적으로 사용되는 방법 중 하나를 계속 적용합니다.
시계열의 미래 지점을 모델링하고 예측하기 위해 Python에서 사용할 수 있는 방법 중 하나는 SARIMAX로 알려져 있으며, 이는 eXogenous regressor가 있는 Seasonal AutoRegressive Integrated Moving Averages를 나타냅니다. 여기서는 시계열의 미래 지점을 더 잘 이해하고 예측하기 위해 시계열 데이터를 맞추는 데 사용되는 ARIMA 구성 요소에 주로 초점을 맞출 것입니다.
전제 조건
이 가이드는 로컬 데스크톱 또는 원격 서버에서 시계열 분석을 수행하는 방법을 다룹니다. 대규모 데이터 세트로 작업하면 메모리를 많이 사용할 수 있으므로 두 경우 모두 이 가이드의 일부 계산을 수행하려면 컴퓨터에 최소 2GB의 메모리가 필요합니다.
이 자습서를 최대한 활용하려면 시계열 및 통계에 대한 지식이 도움이 될 수 있습니다.
이 자습서에서는 Jupyter Notebook을 사용하여 데이터 작업을 수행합니다. 아직 가지고 있지 않다면 자습서에 따라 Python 3용 Jupyter Notebook을 설치하고 설정해야 합니다.
1단계 - 패키지 설치
시계열 예측을 위한 환경을 설정하기 위해 먼저 서버 기반 프로그래밍 환경으로 이동하겠습니다.
- cd environments
- . my_env/bin/activate
여기에서 프로젝트를 위한 새 디렉토리를 생성하겠습니다. 우리는 그것을 ARIMA라고 부르고 그 디렉토리로 이동할 것입니다. 프로젝트를 다른 이름으로 부르는 경우 가이드 전체에서 ARIMA를 자신의 이름으로 대체해야 합니다.
- mkdir ARIMA
- cd ARIMA
이 튜토리얼에는 warnings, itertools, pandas, numpy, matplotlib 및 statsmodels 라이브러리. warnings 및 itertools 라이브러리는 표준 Python 라이브러리 세트에 포함되어 있으므로 설치할 필요가 없습니다.
다른 Python 패키지와 마찬가지로 pip를 사용하여 이러한 요구 사항을 설치할 수 있습니다.
- pip install pandas numpy statsmodels matplotlib
이 시점에서 이제 설치된 패키지 작업을 시작하도록 설정되었습니다.
2단계 - 패키지 가져오기 및 데이터 로드
데이터 작업을 시작하기 위해 Jupyter Notebook을 시작합니다.
- jupyter notebook
새 노트북 파일을 만들려면 오른쪽 상단 풀다운 메뉴에서 새로 만들기 > Python 3을 선택합니다.

그러면 노트북이 열립니다.
가장 좋은 방법은 노트북 상단에 필요한 라이브러리를 가져오는 것부터 시작하는 것입니다.
import warnings
import itertools
import pandas as pd
import numpy as np
import statsmodels.api as sm
import matplotlib.pyplot as plt
plt.style.use('fivethirtyeight')
또한 플롯에 대해 fivethirtyeight의 matplotlib 스타일을 정의했습니다.
우리는 1958년 3월부터 2001년 12월까지 CO2 샘플을 수집한 "Atmospheric CO2 from Continuous Air Samples at Mauna Loa Observatory, Hawaii, U.S.A.\라는 데이터 세트로 작업할 것입니다. 이 데이터를 다음과 같이 가져올 수 있습니다.
data = sm.datasets.co2.load_pandas()
y = data.data
계속 진행하기 전에 데이터를 약간 사전 처리해 보겠습니다. 주간 데이터는 시간이 더 짧기 때문에 작업하기 까다로울 수 있으므로 대신 월간 평균을 사용하겠습니다. resample 함수를 사용하여 변환을 수행합니다. 단순화를 위해 fillna() 함수를 사용하여 시계열에 누락된 값이 없는지 확인할 수도 있습니다.
# The 'MS' string groups the data in buckets by start of the month
y = y['co2'].resample('MS').mean()
# The term bfill means that we use the value before filling in missing values
y = y.fillna(y.bfill())
print(y)
Outputco2
1958-03-01 316.100000
1958-04-01 317.200000
1958-05-01 317.433333
...
2001-11-01 369.375000
2001-12-01 371.020000
이 시계열 e를 데이터 시각화로 살펴보겠습니다.
y.plot(figsize=(15, 6))
plt.show()
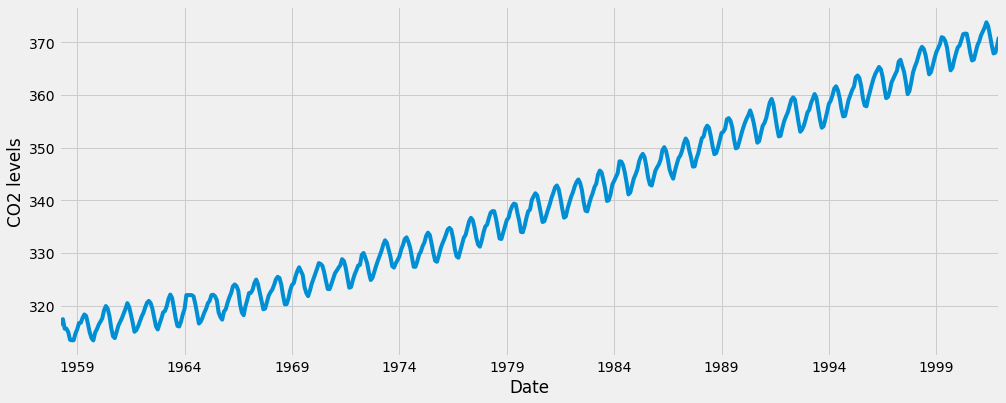
데이터를 플롯할 때 몇 가지 구별 가능한 패턴이 나타납니다. 시계열에는 명백한 계절성 패턴과 전반적인 증가 추세가 있습니다.
시계열 전처리에 대해 자세히 알아보려면 위의 단계가 훨씬 더 자세히 설명되어 있는 \A Guide to Time Series Visualization with Python 3\를 참조하십시오.
이제 데이터를 변환하고 탐색했으므로 ARIMA를 사용한 시계열 예측으로 이동하겠습니다.
3단계 — ARIMA 시계열 모델
시계열 예측에 사용되는 가장 일반적인 방법 중 하나는 AutoregRessive Integrated Moving Average를 나타내는 ARIMA 모델로 알려져 있습니다. ARIMA는 계열의 미래 지점을 더 잘 이해하거나 예측하기 위해 시계열 데이터에 맞출 수 있는 모델입니다.
ARIMA 모델을 매개변수화하는 데 사용되는 세 가지 개별 정수(p, d, q)가 있습니다. 그 때문에 ARIMA 모델은 ARIMA(p, d, q) 표기법으로 표시됩니다. 이 세 가지 매개변수는 함께 데이터세트의 계절성, 추세 및 노이즈를 설명합니다.
p는 모델의 자동 회귀 부분입니다. 이를 통해 과거 값의 효과를 모델에 통합할 수 있습니다. 직관적으로 이것은 지난 3일 동안 따뜻했다면 내일도 따뜻할 것이라고 말하는 것과 비슷합니다.d는 모델의 통합 부분입니다. 여기에는 시계열에 적용할 차이의 양(즉, 현재 값에서 뺄 과거 시점의 수)을 포함하는 모델의 항이 포함됩니다. 직관적으로 이것은 지난 3일 동안의 온도 차이가 매우 작았다면 내일도 같은 온도일 가능성이 높다고 말하는 것과 유사합니다.q는 모델의 이동 평균 부분입니다. 이를 통해 모델의 오류를 과거의 이전 시점에서 관찰된 오류 값의 선형 조합으로 설정할 수 있습니다.
계절 효과를 처리할 때 ARIMA(p,d,q)(P,D,Q)s로 표시되는 계절 ARIMA를 사용합니다. 여기서 (p, d, q)는 위에서 설명한 비계절 매개변수이며, (P, D, Q)는 동일한 정의를 따르지만 계절 매개변수에 적용됩니다. 시계열의 구성 요소. 용어 s는 시계열의 주기성입니다(분기별 기간의 경우 4, 연간 기간의 경우 12 등).
계절 ARIMA 방법은 관련된 여러 조정 매개변수로 인해 어려워 보일 수 있습니다. 다음 섹션에서는 계절 ARIMA 시계열 모델에 대한 최적의 매개변수 집합을 식별하는 프로세스를 자동화하는 방법을 설명합니다.
4단계 - ARIMA 시계열 모델에 대한 매개변수 선택
시계열 데이터를 계절 ARIMA 모델에 맞추려고 할 때 첫 번째 목표는 측정항목을 최적화하는 ARIMA(p,d,q)(P,D,Q)s 값을 찾는 것입니다. 관심. 이 목표를 달성하기 위한 많은 지침과 모범 사례가 있지만 ARIMA 모델의 올바른 매개변수화는 도메인 전문 지식과 시간이 필요한 힘든 수동 프로세스가 될 수 있습니다. R과 같은 다른 통계 프로그래밍 언어는 이 문제를 해결하기 위한 자동화된 방법을 제공하지만 아직 Python으로 포팅되지 않았습니다. 이 섹션에서는 ARIMA(p,d,q)(P,D,Q)s 시계열 모델에 대한 최적의 매개변수 값을 프로그래밍 방식으로 선택하는 Python 코드를 작성하여 이 문제를 해결합니다.
매개변수의 다양한 조합을 반복적으로 탐색하기 위해 "그리드 검색\을 사용할 것입니다. 매개변수의 각 조합에 대해 statsmodels 모듈을 사용하여 전반적인 품질을 평가합니다. 매개변수의 전체 환경을 탐색한 후에 최적의 매개변수 세트는 관심 기준에 대해 최상의 성능을 제공하는 매개변수가 될 것입니다. 매개변수의 다양한 조합을 생성하는 것으로 시작하겠습니다. 우리는 다음을 평가하고자 합니다:
# Define the p, d and q parameters to take any value between 0 and 2
p = d = q = range(0, 2)
# Generate all different combinations of p, q and q triplets
pdq = list(itertools.product(p, d, q))
# Generate all different combinations of seasonal p, q and q triplets
seasonal_pdq = [(x[0], x[1], x[2], 12) for x in list(itertools.product(p, d, q))]
print('Examples of parameter combinations for Seasonal ARIMA...')
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[1]))
print('SARIMAX: {} x {}'.format(pdq[1], seasonal_pdq[2]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[3]))
print('SARIMAX: {} x {}'.format(pdq[2], seasonal_pdq[4]))
OutputExamples of parameter combinations for Seasonal ARIMA...
SARIMAX: (0, 0, 1) x (0, 0, 1, 12)
SARIMAX: (0, 0, 1) x (0, 1, 0, 12)
SARIMAX: (0, 1, 0) x (0, 1, 1, 12)
SARIMAX: (0, 1, 0) x (1, 0, 0, 12)
이제 위에서 정의한 세 가지 매개변수를 사용하여 다양한 조합에서 ARIMA 모델을 교육하고 평가하는 과정을 자동화할 수 있습니다. 통계 및 기계 학습에서는 이 프로세스를 모델 선택을 위한 그리드 검색(또는 하이퍼 매개변수 최적화)이라고 합니다.
서로 다른 매개변수가 적용된 통계 모델을 평가하고 비교할 때 각각은 데이터에 얼마나 잘 맞는지 또는 미래 데이터 포인트를 정확하게 예측하는 능력에 따라 서로 순위를 매길 수 있습니다. statsmodels를 사용하여 적합된 ARIMA 모델로 편리하게 반환되는 AIC(Akaike Information Criterion) 값을 사용합니다. AIC는 모델의 전반적인 복잡성을 고려하면서 모델이 데이터에 얼마나 잘 맞는지 측정합니다. 많은 기능을 사용하면서 데이터에 매우 잘 맞는 모델에는 동일한 적합도를 달성하기 위해 더 적은 기능을 사용하는 모델보다 더 큰 AIC 점수가 할당됩니다. 따라서 가장 낮은 AIC 값을 생성하는 모델을 찾는 데 관심이 있습니다.
아래의 코드 청크는 매개변수 조합을 반복하고 statsmodels의 SARIMAX 함수를 사용하여 해당 계절 ARIMA 모델에 맞춥니다. 여기서 order 인수는 (p, d, q) 매개변수를 지정하고 seasonal_order 인수는 (P, D , Q, S) 계절 ARIMA 모델의 계절 구성요소입니다. 각 SARIMAX()모델을 맞춘 후 코드는 해당 AIC 점수를 출력합니다.
warnings.filterwarnings("ignore") # specify to ignore warning messages
for param in pdq:
for param_seasonal in seasonal_pdq:
try:
mod = sm.tsa.statespace.SARIMAX(y,
order=param,
seasonal_order=param_seasonal,
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print('ARIMA{}x{}12 - AIC:{}'.format(param, param_seasonal, results.aic))
except:
continue
일부 매개변수 조합으로 인해 숫자가 잘못 지정될 수 있으므로 경고 메시지의 과부하를 방지하기 위해 명시적으로 경고 메시지를 비활성화했습니다. 이러한 잘못된 사양은 또한 오류로 이어지고 예외를 발생시킬 수 있으므로 이러한 예외를 포착하고 이러한 문제를 일으키는 매개변수 조합을 무시합니다.
위의 코드는 다음과 같은 결과를 생성해야 하며 시간이 다소 걸릴 수 있습니다.
OutputSARIMAX(0, 0, 0)x(0, 0, 1, 12) - AIC:6787.3436240402125
SARIMAX(0, 0, 0)x(0, 1, 1, 12) - AIC:1596.711172764114
SARIMAX(0, 0, 0)x(1, 0, 0, 12) - AIC:1058.9388921320026
SARIMAX(0, 0, 0)x(1, 0, 1, 12) - AIC:1056.2878315690562
SARIMAX(0, 0, 0)x(1, 1, 0, 12) - AIC:1361.6578978064144
SARIMAX(0, 0, 0)x(1, 1, 1, 12) - AIC:1044.7647912940095
...
...
...
SARIMAX(1, 1, 1)x(1, 0, 0, 12) - AIC:576.8647112294245
SARIMAX(1, 1, 1)x(1, 0, 1, 12) - AIC:327.9049123596742
SARIMAX(1, 1, 1)x(1, 1, 0, 12) - AIC:444.12436865161305
SARIMAX(1, 1, 1)x(1, 1, 1, 12) - AIC:277.7801413828764
우리 코드의 출력은 SARIMAX(1, 1, 1)x(1, 1, 1, 12)가 가장 낮은 AIC 값인 277.78을 산출함을 시사합니다. 따라서 우리는 이것을 우리가 고려한 모든 모델 중에서 최적의 옵션으로 간주해야 합니다.
5단계 — ARIMA 시계열 모델 피팅
그리드 검색을 사용하여 시계열 데이터에 가장 적합한 모델을 생성하는 매개변수 세트를 식별했습니다. 이 특정 모델을 더 깊이 있게 분석할 수 있습니다.
최적의 매개변수 값을 새 SARIMAX 모델에 연결하여 시작하겠습니다.
mod = sm.tsa.statespace.SARIMAX(y,
order=(1, 1, 1),
seasonal_order=(1, 1, 1, 12),
enforce_stationarity=False,
enforce_invertibility=False)
results = mod.fit()
print(results.summary().tables[1])
Output==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ar.L1 0.3182 0.092 3.443 0.001 0.137 0.499
ma.L1 -0.6255 0.077 -8.165 0.000 -0.776 -0.475
ar.S.L12 0.0010 0.001 1.732 0.083 -0.000 0.002
ma.S.L12 -0.8769 0.026 -33.811 0.000 -0.928 -0.826
sigma2 0.0972 0.004 22.634 0.000 0.089 0.106
==============================================================================
SARIMAX의 출력 결과인 summary 속성은 상당한 양의 정보를 반환하지만 계수 테이블에 집중하겠습니다. 계수 열은 각 기능의 가중치(즉, 중요도)와 각 기능이 시계열에 미치는 영향을 보여줍니다. P>|z| 열은 각 기능 가중치의 중요성을 알려줍니다. 여기서 각 가중치의 p-값은 0.05에 가깝거나 낮으므로 모델에 모두 유지하는 것이 합리적입니다.
계절 ARIMA 모델(및 해당 문제에 대한 다른 모델)을 피팅할 때 모델 진단을 실행하여 모델에서 만든 가정이 위반되지 않았는지 확인하는 것이 중요합니다. plot_diagnostics 개체를 사용하면 모델 진단을 신속하게 생성하고 비정상적인 동작을 조사할 수 있습니다.
results.plot_diagnostics(figsize=(15, 12))
plt.show()
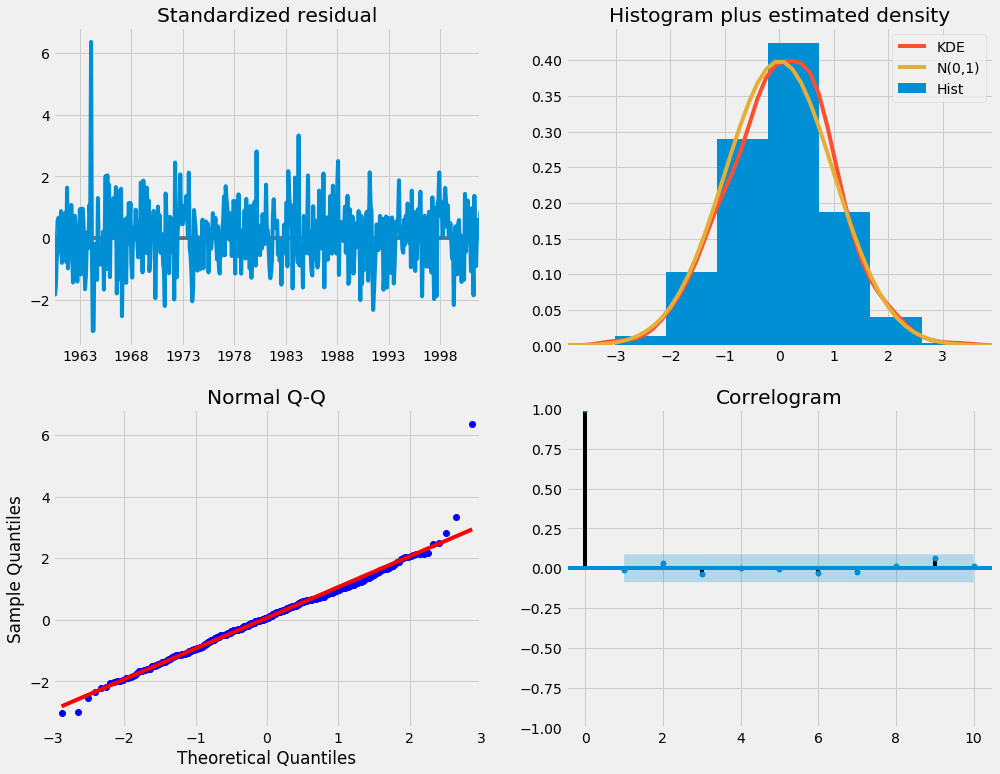
우리의 주요 관심사는 모델의 잔차가 상관되지 않고 평균이 0으로 정규 분포되도록 하는 것입니다. 계절 ARIMA 모델이 이러한 속성을 만족하지 않는 경우 더 개선할 수 있다는 좋은 지표입니다.
이 경우 모델 진단은 모델 잔차가 다음을 기반으로 정규 분포됨을 제안합니다.
- 오른쪽 상단 플롯에서 빨간색
KDE라인이N(0,1)라인(여기서N(0,1))는 평균이0이고 표준 편차가1인 정규 분포의 표준 표기법입니다. 이는 잔차가 정규 분포를 따른다는 좋은 지표입니다.\n - 왼쪽 하단의 qq-plot은 잔차(파란색 점)의 정렬된 분포가
N(0, 1)의 표준 정규 분포에서 가져온 샘플의 선형 추세를 따른다는 것을 보여줍니다. 다시 말하지만 이것은 잔차가 정규 분포를 따른다는 강력한 표시입니다.\n - 시간 경과에 따른 잔차(왼쪽 상단 플롯)는 뚜렷한 계절성을 나타내지 않으며 백색 잡음으로 나타납니다. 이는 오른쪽 하단의 자기상관(즉, 상관도) 플롯으로 확인되며, 이는 시계열 잔차가 자체의 지연된 버전과 낮은 상관관계를 가짐을 보여줍니다.\n
이러한 관찰을 통해 모델이 시계열 데이터를 이해하고 미래 값을 예측하는 데 도움이 될 수 있는 만족스러운 적합성을 생성한다는 결론을 내립니다.
적합도가 만족스럽지만 계절성 ARIMA 모델의 일부 매개변수를 변경하여 모델 적합도를 개선할 수 있습니다. 예를 들어 그리드 검색은 제한된 매개변수 조합 집합만 고려했기 때문에 그리드 검색을 넓히면 더 나은 모델을 찾을 수 있습니다.
6단계 - 예측 검증
이제 예측을 생성하는 데 사용할 수 있는 시계열 모델을 얻었습니다. 예측 값을 시계열의 실제 값과 비교하는 것으로 시작하여 예측의 정확성을 이해하는 데 도움이 됩니다. get_prediction() 및 conf_int() 속성을 사용하면 시계열 예측에 대한 값 및 관련 신뢰 구간을 얻을 수 있습니다.
pred = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=False)
pred_ci = pred.conf_int()
위의 코드는 예측이 1998년 1월에 시작하도록 요구합니다.
dynamic=False 인수는 우리가 한 단계 앞선 예측을 생성하도록 보장합니다. 즉, 각 지점에서 해당 지점까지의 전체 기록을 사용하여 예측이 생성됩니다.
CO2 시계열의 실제 값과 예상 값을 플롯하여 얼마나 잘 수행했는지 평가할 수 있습니다. 날짜 인덱스를 분할하여 시계열의 끝 부분을 어떻게 확대했는지 확인하십시오.
ax = y['1990':].plot(label='observed')
pred.predicted_mean.plot(ax=ax, label='One-step ahead Forecast', alpha=.7)
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.2)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()

전반적으로 우리의 예측은 실제 값과 매우 잘 일치하여 전반적인 증가 추세를 보여줍니다.
예측의 정확도를 정량화하는 것도 유용합니다. 예측의 평균 오차를 요약한 MSE(Mean Squared Error)를 사용합니다. 각 예측 값에 대해 실제 값까지의 거리를 계산하고 결과를 제곱합니다. 전체 평균을 계산할 때 양수/음수 차이가 서로 상쇄되지 않도록 결과를 제곱해야 합니다.
y_forecasted = pred.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
OutputThe Mean Squared Error of our forecasts is 0.07
한 단계 앞선 예측의 MSE는 0.07의 값을 산출하는데, 이는 0에 가깝기 때문에 매우 낮습니다. MSE가 0이면 추정기가 완벽한 정확도로 매개변수의 관찰을 예측하고 있다는 것입니다. , 이상적인 시나리오이지만 일반적으로 불가능합니다.
그러나 동적 예측을 사용하면 진정한 예측력을 더 잘 표현할 수 있습니다. 이 경우 특정 시점까지의 시계열 정보만 사용하고 그 이후에는 이전 예측 시점의 값을 사용하여 예측을 생성합니다.
아래 코드 청크에서 1998년 1월부터 동적 예측 및 신뢰 구간 계산을 시작하도록 지정합니다.
pred_dynamic = results.get_prediction(start=pd.to_datetime('1998-01-01'), dynamic=True, full_results=True)
pred_dynamic_ci = pred_dynamic.conf_int()
시계열의 관찰 및 예측 값을 플로팅하면 동적 예측을 사용하는 경우에도 전체 예측이 정확함을 알 수 있습니다. 모든 예측 값(빨간색 선)은 실측 값(파란색 선)과 거의 일치하며 예측의 신뢰 구간 내에 있습니다.
ax = y['1990':].plot(label='observed', figsize=(20, 15))
pred_dynamic.predicted_mean.plot(label='Dynamic Forecast', ax=ax)
ax.fill_between(pred_dynamic_ci.index,
pred_dynamic_ci.iloc[:, 0],
pred_dynamic_ci.iloc[:, 1], color='k', alpha=.25)
ax.fill_betweenx(ax.get_ylim(), pd.to_datetime('1998-01-01'), y.index[-1],
alpha=.1, zorder=-1)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
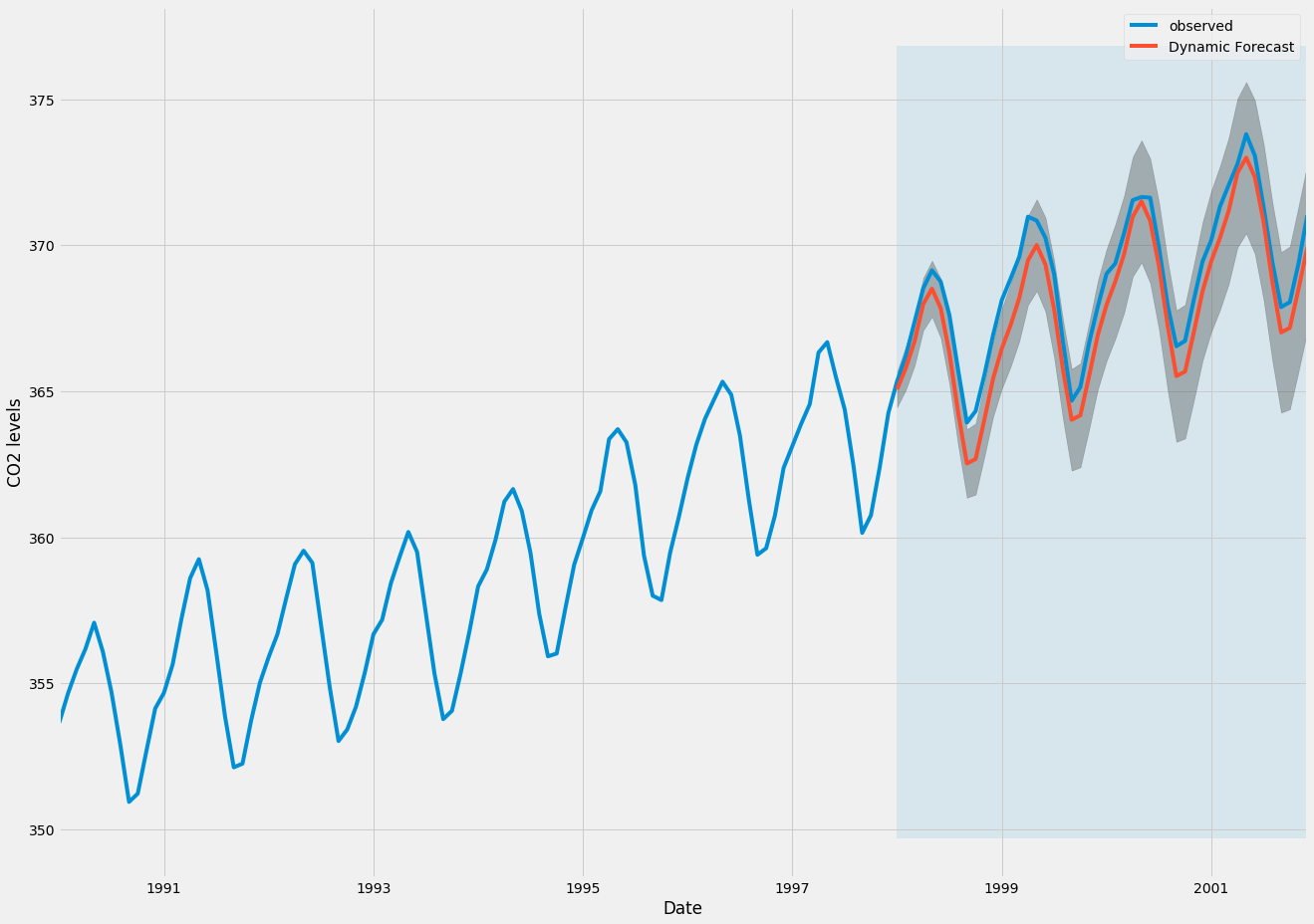
다시 한 번 MSE를 계산하여 예측의 예측 성능을 정량화합니다.
# Extract the predicted and true values of our time series
y_forecasted = pred_dynamic.predicted_mean
y_truth = y['1998-01-01':]
# Compute the mean square error
mse = ((y_forecasted - y_truth) ** 2).mean()
print('The Mean Squared Error of our forecasts is {}'.format(round(mse, 2)))
OutputThe Mean Squared Error of our forecasts is 1.01
동적 예측에서 얻은 예측 값은 1.01의 MSE를 산출합니다. 이것은 우리가 시계열의 과거 데이터에 덜 의존하고 있다는 점을 감안할 때 예상되는 한 단계 앞선 것보다 약간 높습니다.
한 단계 앞선 예측과 동적 예측 모두 이 시계열 모델이 유효함을 확인합니다. 그러나 시계열 예측에 대한 관심의 상당 부분은 훨씬 앞서 미래 가치를 예측할 수 있는 능력입니다.
7단계 - 예측 생성 및 시각화
이 자습서의 마지막 단계에서는 계절성 ARIMA 시계열 모델을 활용하여 미래 값을 예측하는 방법을 설명합니다. 시계열 객체의 get_forecast() 속성은 앞으로 지정된 단계 수에 대한 예측 값을 계산할 수 있습니다.
# Get forecast 500 steps ahead in future
pred_uc = results.get_forecast(steps=500)
# Get confidence intervals of forecasts
pred_ci = pred_uc.conf_int()
이 코드의 출력을 사용하여 미래 값의 시계열 및 예측을 그릴 수 있습니다.
ax = y.plot(label='observed', figsize=(20, 15))
pred_uc.predicted_mean.plot(ax=ax, label='Forecast')
ax.fill_between(pred_ci.index,
pred_ci.iloc[:, 0],
pred_ci.iloc[:, 1], color='k', alpha=.25)
ax.set_xlabel('Date')
ax.set_ylabel('CO2 Levels')
plt.legend()
plt.show()
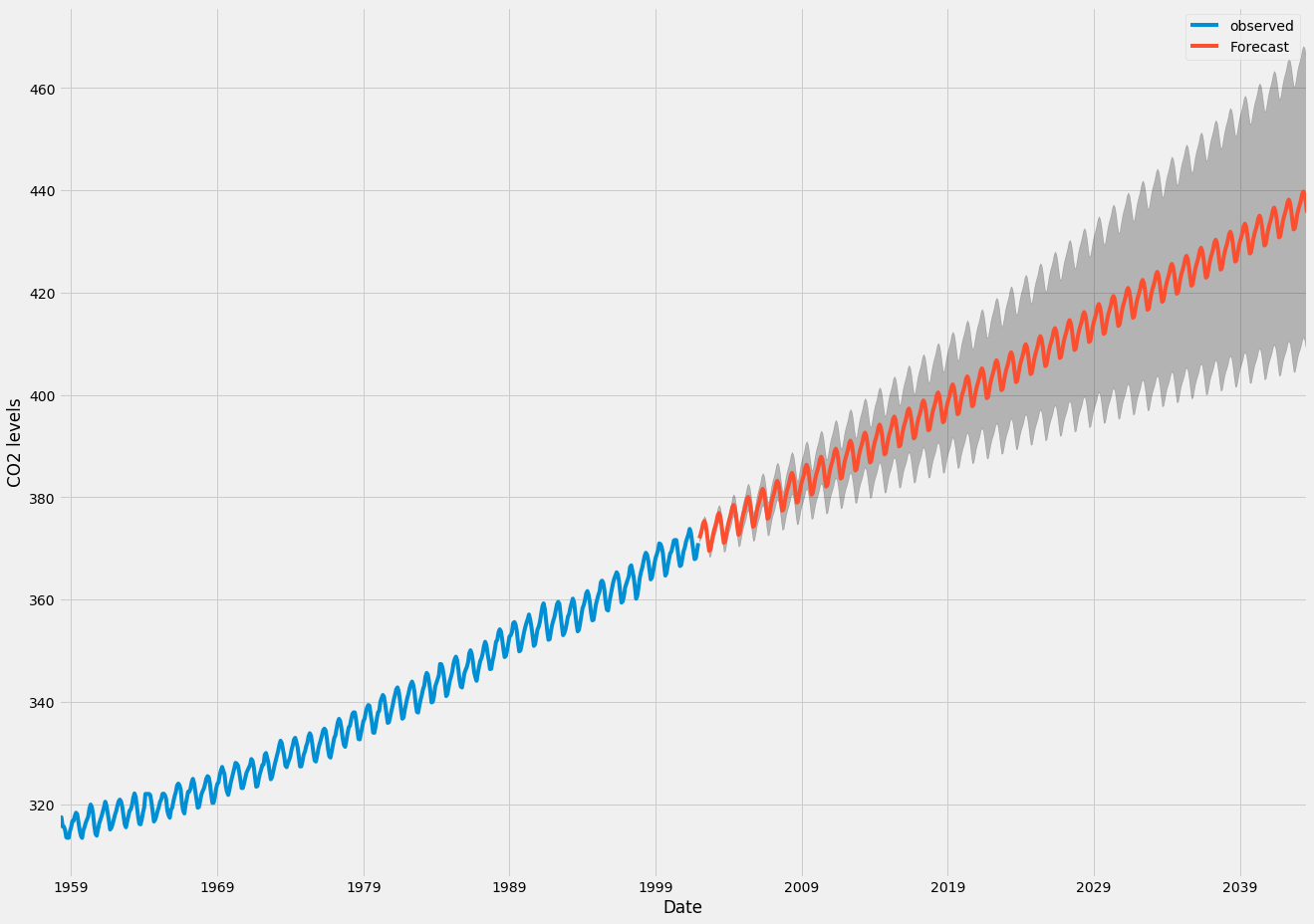
이제 우리가 생성한 예측 및 관련 신뢰 구간을 모두 사용하여 시계열을 더 자세히 이해하고 무엇을 예상할지 예측할 수 있습니다. 우리의 예측에 따르면 시계열은 꾸준한 속도로 계속 증가할 것으로 예상됩니다.
우리가 미래를 더 멀리 내다볼수록 우리의 가치에 대한 자신감이 떨어지는 것은 당연합니다. 이는 모델에서 생성된 신뢰 구간에 반영되며, 이는 미래로 갈수록 더 커집니다.
결론
이 자습서에서는 Python에서 계절 ARIMA 모델을 구현하는 방법을 설명했습니다. 우리는 pandas 및 statsmodels 라이브러리를 광범위하게 사용하고 모델 진단을 실행하는 방법과 CO2 시계열 예측을 생성하는 방법을 보여주었습니다.
시도해 볼 수 있는 몇 가지 다른 작업은 다음과 같습니다.
- 동적 예측의 시작 날짜를 변경하여 예측의 전반적인 품질에 어떤 영향을 미치는지 확인하십시오.
- 더 많은 매개변수 조합을 시도하여 모델의 적합도를 개선할 수 있는지 확인하세요.
- 최상의 모델을 선택하려면 다른 측정항목을 선택하세요. 예를 들어
AIC측정을 사용하여 최상의 모델을 찾았지만 대신 표본 외 평균 제곱 오차를 최적화할 수 있습니다.
더 많은 연습을 위해 다른 시계열 데이터 세트를 로드하여 자체 예측을 생성할 수도 있습니다.