Kubernetes에서 Elasticsearch, Fluentd 및 Kibana(EFK) 로깅 스택을 설정하는 방법
소개
Kubernetes 클러스터에서 여러 서비스 및 애플리케이션을 실행할 때 중앙 집중식 클러스터 수준 로깅 스택을 사용하면 Pod에서 생성된 많은 양의 로그 데이터를 빠르게 정렬하고 분석할 수 있습니다. 널리 사용되는 중앙 집중식 로깅 솔루션 중 하나는 Elasticsearch, Fluentd 및 Kibana(EFK) 스택입니다.
Elasticsearch는 전체 텍스트 및 구조화된 검색과 분석을 허용하는 확장 가능한 실시간 분산 검색 엔진입니다. 대용량의 로그 데이터를 인덱싱하고 검색하는 데 일반적으로 사용되지만 다양한 종류의 문서를 검색하는 데에도 사용할 수 있습니다.
Elasticsearch는 일반적으로 강력한 데이터 시각화 프런트엔드이자 Elasticsearch용 대시보드인 Kibana와 함께 배포됩니다. Kibana를 사용하면 웹 인터페이스를 통해 Elasticsearch 로그 데이터를 탐색하고 대시보드와 쿼리를 구축하여 질문에 빠르게 답하고 Kubernetes 애플리케이션에 대한 통찰력을 얻을 수 있습니다.
이 튜토리얼에서는 Fluentd를 사용하여 로그 데이터를 수집, 변환하고 Elasticsearch 백엔드로 배송합니다. Fluentd는 인기 있는 오픈 소스 데이터 수집기로 Kubernetes 노드에 설정하여 컨테이너 로그 파일을 추적하고, 로그 데이터를 필터링 및 변환하고, 이를 Elasticsearch 클러스터로 전달하여 인덱싱 및 저장합니다.
확장 가능한 Elasticsearch 클러스터를 구성 및 실행하는 것으로 시작한 다음 Kibana Kubernetes 서비스 및 배포를 생성합니다. 결론적으로 Fluentd를 DaemonSet으로 설정하여 모든 Kubernetes 작업자 노드에서 실행되도록 하겠습니다.
전제 조건
이 안내서를 시작하기 전에 다음을 사용할 수 있는지 확인하십시오.
- RBAC(역할 기반 액세스 제어)가 활성화된 Kubernetes 1.10+ 클러스터\n
- 클러스터에 EFK 스택을 롤아웃하는 데 사용할 수 있는 리소스가 충분한지 확인하고, 그렇지 않은 경우 작업자 노드를 추가하여 클러스터를 확장합니다. 3-Pod Elasticsearch 클러스터(필요한 경우 1개로 축소 가능)와 단일 Kibana Pod를 배포할 예정입니다. 모든 작업자 노드는 Fluentd Pod도 실행합니다. 이 가이드의 클러스터는 3개의 작업자 노드와 관리형 제어 영역으로 구성됩니다.
클러스터에 연결하도록 구성된 로컬 머신에 설치된
kubectl명령줄 도구. 공식 문서에서kubectl설치에 대해 자세히 알아볼 수 있습니다.이러한 구성 요소를 설정했으면 이 가이드를 시작할 준비가 된 것입니다.
1단계 - 네임스페이스 생성
Elasticsearch 클러스터를 출시하기 전에 먼저 모든 로깅 도구를 설치할 네임스페이스를 생성합니다. Kubernetes를 사용하면 네임스페이스라는 "가상 클러스터\ 추상화를 사용하여 클러스터에서 실행 중인 개체를 분리할 수 있습니다. 이 가이드에서는 EFK 스택 구성 요소를 설치할
kube-logging네임스페이스를 생성합니다. . 이 네임스페이스를 사용하면 Kubernetes 클러스터에 대한 기능 손실 없이 로깅 스택을 신속하게 정리하고 제거할 수 있습니다.시작하려면 먼저
kubectl을 사용하여 클러스터의 기존 네임스페이스를 조사합니다.- kubectl get namespaces
Kubernetes 클러스터와 함께 사전 설치된 다음 세 가지 초기 네임스페이스가 표시되어야 합니다.
OutputNAME STATUS AGE default Active 5m kube-system Active 5m kube-public Active 5m기본네임스페이스는 네임스페이스를 지정하지 않고 생성된 개체를 수용합니다.kube-system네임스페이스에는kube-dns,kube-proxy및kubernetes와 같은 Kubernetes 시스템에서 생성하고 사용하는 객체가 포함됩니다. -대시보드. 이 네임스페이스를 깨끗하게 유지하고 애플리케이션 및 계측 워크로드로 오염시키지 않는 것이 좋습니다.kube-public네임스페이스는 인증되지 않은 사용자도 전체 클러스터에서 읽고 액세스할 수 있도록 하려는 개체를 저장하는 데 사용할 수 있는 자동으로 생성된 또 다른 네임스페이스입니다.kube-logging네임스페이스를 생성하려면 먼저 nano와 같이 즐겨 사용하는 편집기를 사용하여kube-logging.yaml이라는 파일을 열고 편집합니다.- nano kube-logging.yaml
편집기 내에서 다음 네임스페이스 객체 YAML을 붙여넣습니다.
kind: Namespace apiVersion: v1 metadata: name: kube-logging그런 다음 파일을 저장하고 닫습니다.
여기서는 Kubernetes 개체의
종류를Namespace개체로 지정합니다.네임스페이스개체에 대해 자세히 알아보려면 공식 Kubernetes 설명서의 네임스페이스 둘러보기를 참조하세요. 또한 개체를 생성하는 데 사용되는 Kubernetes API 버전(v1)을 지정하고이름,kube-logging을 지정합니다.kube-logging.yaml네임스페이스 개체 파일을 생성했으면-f파일 이름 플래그와 함께kubectl create를 사용하여 네임스페이스를 생성합니다.- kubectl create -f kube-logging.yaml
다음 출력이 표시되어야 합니다.
Outputnamespace/kube-logging created그런 다음 네임스페이스가 성공적으로 생성되었는지 확인할 수 있습니다.
- kubectl get namespaces
이 시점에서 새
kube-logging네임스페이스가 표시되어야 합니다.OutputNAME STATUS AGE default Active 23m kube-logging Active 1m kube-public Active 23m kube-system Active 23m이제 이 격리된 로깅 네임스페이스에 Elasticsearch 클러스터를 배포할 수 있습니다.
2단계 — Elasticsearch StatefulSet 생성
이제 로깅 스택을 보관할 네임스페이스를 만들었으므로 다양한 구성 요소를 롤아웃할 수 있습니다. 먼저 3노드 Elasticsearch 클러스터를 배포하는 것으로 시작하겠습니다.
이 가이드에서는 고가용성 다중 노드 클러스터에서 발생하는 "split-brain\ 문제를 피하기 위해 3개의 Elasticsearch Pod를 사용합니다. 상위 수준에서 "split-brain\은 하나 이상의 노드는 다른 노드와 통신할 수 없으며 여러 "분할\ 마스터가 선출됩니다. 3개의 노드를 사용하면 한 노드가 클러스터에서 일시적으로 연결이 끊어지면 다른 두 노드가 새 마스터를 선출할 수 있고 클러스터는 마지막 노드가 계속 작동하는 동안 계속 작동할 수 있습니다. 노드가 다시 가입을 시도합니다. 자세한 내용은 투표 구성을 참조하세요.
헤드리스 서비스 만들기
시작하려면 3개의 포드에 대한 DNS 도메인을 정의할
elasticsearch라는 헤드리스 Kubernetes 서비스를 생성합니다. 헤드리스 서비스는 로드 밸런싱을 수행하지 않거나 고정 IP를 갖지 않습니다. 헤드리스 서비스에 대한 자세한 내용은 공식 Kubernetes 문서를 참조하세요.원하는 편집기를 사용하여
elasticsearch_svc.yaml파일을 엽니다.- nano elasticsearch_svc.yaml
다음 Kubernetes 서비스 YAML을 붙여넣습니다.
kind: Service apiVersion: v1 metadata: name: elasticsearch namespace: kube-logging labels: app: elasticsearch spec: selector: app: elasticsearch clusterIP: None ports: - port: 9200 name: rest - port: 9300 name: inter-node그런 다음 파일을 저장하고 닫습니다.
kube-logging네임스페이스에elasticsearch라는Service를 정의하고app: elasticsearch레이블을 지정합니다. 그런 다음 서비스가app: elasticsearch레이블이 있는 포드를 선택하도록.spec.selector를app: elasticsearch로 설정합니다. Elasticsearch StatefulSet를 이 서비스와 연결하면 서비스는app: elasticsearch레이블이 있는 Elasticsearch 포드를 가리키는 DNS A 레코드를 반환합니다.그런 다음 서비스를 헤드리스로 렌더링하는
clusterIP: None을 설정합니다. 마지막으로 REST API와 상호 작용하고 노드 간 통신에 사용되는 포트9200및9300을 각각 정의합니다.kubectl을 사용하여 서비스를 생성합니다.- kubectl create -f elasticsearch_svc.yaml
다음 출력이 표시되어야 합니다.
Outputservice/elasticsearch created마지막으로
kubectl get을 사용하여 서비스가 성공적으로 생성되었는지 다시 확인합니다.kubectl get services --namespace=kube-logging다음이 표시되어야 합니다.
OutputNAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE elasticsearch ClusterIP None <none> 9200/TCP,9300/TCP 26s헤드리스 서비스와 포드에 대한 안정적인
.elasticsearch.kube-logging.svc.cluster.local도메인을 설정했으므로 이제 StatefulSet를 생성할 수 있습니다.스테이트풀셋 생성
Kubernetes StatefulSet를 사용하면 포드에 안정적인 ID를 할당하고 안정적이고 지속적인 스토리지를 부여할 수 있습니다. Elasticsearch는 Pod 재예약 및 재시작에서 데이터를 유지하기 위해 안정적인 스토리지가 필요합니다. StatefulSet 워크로드에 대해 자세히 알아보려면 Kubernetes 문서에서 Statefulsets 페이지를 참조하세요.
원하는 편집기에서
elasticsearch_statefulset.yaml파일을 엽니다.- nano elasticsearch_statefulset.yaml
StatefulSet 개체 정의 섹션을 섹션별로 이동하여 블록을 이 파일에 붙여넣습니다.
다음 블록을 붙여넣기 시작합니다.
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: kube-logging spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch이 블록에서는
kube-logging네임스페이스에es-cluster라는 StatefulSet를 정의합니다. 그런 다음serviceName필드를 사용하여 이전에 만든elasticsearch서비스와 연결합니다. 이렇게 하면 다음 DNS 주소를 사용하여 StatefulSet의 각 Pod에 액세스할 수 있습니다.es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local, 여기서 <[0,1,2]는 Pod의 할당된 정수 서수에 해당합니다.3개의
replicas(Pod)를 지정하고matchLabels선택기를app: elasticseach로 설정한 다음.spec에서 미러링합니다. template.metadata섹션..spec.selector.matchLabels및.spec.template.metadata.labels필드는 일치해야 합니다.이제 개체 사양으로 이동할 수 있습니다. 이전 블록 바로 아래에 다음 YAML 블록을 붙여넣습니다.
. . . spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: k8s-logs - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m"여기에서 StatefulSet의 포드를 정의합니다. 컨테이너 이름을
elasticsearch로 지정하고docker.elastic.co/elasticsearch/elasticsearch:7.2.0Docker 이미지를 선택합니다. 이 시점에서 이 이미지 태그를 자체 내부 Elasticsearch 이미지 또는 다른 버전에 맞게 수정할 수 있습니다. 이 가이드의 목적상 Elasticsearch7.2.0만 테스트되었습니다.그런 다음
resources필드를 사용하여 컨테이너에 보장된 최소 0.1 vCPU가 필요하고 최대 1 vCPU까지 버스트할 수 있음을 지정합니다(초기 대규모 수집을 수행하거나 처리할 때 Pod의 리소스 사용량을 제한함). 로드 스파이크). 예상 로드 및 사용 가능한 리소스에 따라 이러한 값을 수정해야 합니다. 리소스 요청 및 제한에 대해 자세히 알아보려면 공식 Kubernetes 설명서를 참조하세요.그런 다음 REST API 및 노드 간 통신을 위해 각각
9200및9300포트를 열고 이름을 지정합니다. 우리는data라는 이름의 PersistentVolume을/usr/share/elasticsearch/ 경로의 컨테이너에 마운트할. 이후 YAML 블록에서 이 StatefulSet에 대한 VolumeClaims를 정의할 것입니다.data라는volumeMount를 지정합니다. 데이터마지막으로 컨테이너에 몇 가지 환경 변수를 설정합니다.
cluster.name: Elasticsearch 클러스터의 이름입니다. 이 가이드에서는k8s-logs입니다.node.name:valueFrom을 사용하여.metadata.name필드로 설정한 노드의 이름입니다. 이는 노드의 할당된 서수에 따라es-cluster-[0,1,2]로 해석됩니다.discovery.seed_hosts: 이 필드는 노드 검색 프로세스를 시드할 클러스터의 마스터 적격 노드 목록을 설정합니다. 이 가이드에서는 앞에서 구성한 헤드리스 서비스 덕분에 포드에es-cluster-[0,1,2].elasticsearch.kube-logging.svc.cluster.local형식의 도메인이 있습니다. , 그래서 우리는 그에 따라 이 변수를 설정합니다. 로컬 네임스페이스 Kubernetes DNS 확인을 사용하여es-cluster-[0,1,2].elasticsearch로 단축할 수 있습니다. Elasticsearch 검색에 대해 자세히 알아보려면 공식 Elasticsearch 문서를 참조하세요.cluster.initial_master_nodes: 이 필드는 마스터 선택 프로세스에 참여할 마스터 적격 노드 목록도 지정합니다. 이 필드의 경우 호스트 이름이 아닌node.name으로 노드를 식별해야 합니다.ES_JAVA_OPTS: 여기에서 JVM이 512MB의 최소 및 최대 힙 크기를 사용하도록 지시하는-Xms512m -Xmx512m로 설정합니다. 클러스터의 리소스 가용성 및 요구 사항에 따라 이러한 매개변수를 조정해야 합니다. 자세한 내용은 힙 크기 설정을 참조하세요.
붙여넣을 다음 블록은 다음과 같습니다.
. . . initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true이 블록에서 기본
elasticsearch앱 컨테이너 전에 실행되는 여러 초기 컨테이너를 정의합니다. 이러한 초기화 컨테이너는 각각 정의된 순서대로 완료될 때까지 실행됩니다. 초기화 컨테이너에 대해 자세히 알아보려면 공식 Kubernetes 문서를 참조하세요.첫 번째
fix-permissions는chown명령을 실행하여 Elasticsearch 데이터 디렉토리의 소유자와 그룹을1000:1000으로 변경합니다. Elasticsearch 사용자의 UID. 기본적으로 Kubernetes는 데이터 디렉토리를root로 마운트하여 Elasticsearch에 액세스할 수 없도록 합니다. 이 단계에 대해 자세히 알아보려면 Elasticsearch의 "프로덕션 사용 및 기본값에 대한 참고 사항\을 참조하십시오.increase-vm-max-map이라는 이름의 두 번째는 mmap 수에 대한 운영 체제의 제한을 늘리는 명령을 실행합니다. 이 제한은 기본적으로 너무 낮아 메모리 부족 오류가 발생할 수 있습니다. 이 단계에 대해 자세히 알아보려면 공식 Elasticsearch 설명서를 참조하십시오.다음으로 실행할 초기화 컨테이너는
increase-fd-ulimit이며, 이는ulimit명령을 실행하여 열린 파일 디스크립터의 최대 수를 늘립니다. 이 단계에 대해 자세히 알아보려면 공식 Elasticsearch 문서에서 "생산 사용 및 기본값에 대한 참고 사항\을 참조하십시오.참고: 프로덕션 사용을 위한 Elasticsearch 노트에서도 성능상의 이유로 스와핑 비활성화에 대해 언급합니다. Kubernetes 설치 또는 공급자에 따라 스와핑이 이미 비활성화되었을 수 있습니다. 이를 확인하려면 실행 중인 컨테이너로
exec하고cat /proc/swaps를 실행하여 활성 스왑 장치를 나열합니다. 아무 것도 표시되지 않으면 스왑이 비활성화된 것입니다.이제 기본 앱 컨테이너와 컨테이너 OS를 조정하기 위해 실행되는 초기화 컨테이너를 정의했으므로 StatefulSet 객체 정의 파일에 마지막 부분인
volumeClaimTemplates를 추가할 수 있습니다.다음
volumeClaimTemplate블록을 붙여넣습니다.. . . volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: do-block-storage resources: requests: storage: 100Gi이 블록에서 우리는 StatefulSet의
volumeClaimTemplates를 정의합니다. Kubernetes는 이를 사용하여 포드에 대한 PersistentVolume을 생성합니다. 위의 블록에서data(이전에 정의한volumeMount에서 참조하는이름임)의 이름을 지정하고 StatefulSet과 동일한app: elasticsearch레이블입니다.그런 다음 액세스 모드를
ReadWriteOnce로 지정합니다. 즉, 단일 노드에서 읽기-쓰기로만 마운트할 수 있습니다. 데모용으로 DigitalOcean Kubernetes 클러스터를 사용하므로 이 가이드에서는 스토리지 클래스를do-block-storage로 정의합니다. Kubernetes 클러스터를 실행 중인 위치에 따라 이 값을 변경해야 합니다. 자세한 내용은 영구 볼륨 설명서를 참조하십시오.마지막으로 각 PersistentVolume의 크기를 100GiB로 지정합니다. 생산 요구 사항에 따라 이 값을 조정해야 합니다.
완전한 StatefulSet 사양은 다음과 같아야 합니다.
apiVersion: apps/v1 kind: StatefulSet metadata: name: es-cluster namespace: kube-logging spec: serviceName: elasticsearch replicas: 3 selector: matchLabels: app: elasticsearch template: metadata: labels: app: elasticsearch spec: containers: - name: elasticsearch image: docker.elastic.co/elasticsearch/elasticsearch:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m ports: - containerPort: 9200 name: rest protocol: TCP - containerPort: 9300 name: inter-node protocol: TCP volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data env: - name: cluster.name value: k8s-logs - name: node.name valueFrom: fieldRef: fieldPath: metadata.name - name: discovery.seed_hosts value: "es-cluster-0.elasticsearch,es-cluster-1.elasticsearch,es-cluster-2.elasticsearch" - name: cluster.initial_master_nodes value: "es-cluster-0,es-cluster-1,es-cluster-2" - name: ES_JAVA_OPTS value: "-Xms512m -Xmx512m" initContainers: - name: fix-permissions image: busybox command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"] securityContext: privileged: true volumeMounts: - name: data mountPath: /usr/share/elasticsearch/data - name: increase-vm-max-map image: busybox command: ["sysctl", "-w", "vm.max_map_count=262144"] securityContext: privileged: true - name: increase-fd-ulimit image: busybox command: ["sh", "-c", "ulimit -n 65536"] securityContext: privileged: true volumeClaimTemplates: - metadata: name: data labels: app: elasticsearch spec: accessModes: [ "ReadWriteOnce" ] storageClassName: do-block-storage resources: requests: storage: 100GiElasticsearch 구성에 만족하면 파일을 저장하고 닫습니다.
이제
kubectl을 사용하여 StatefulSet를 배포합니다.- kubectl create -f elasticsearch_statefulset.yaml
다음 출력이 표시되어야 합니다.
Outputstatefulset.apps/es-cluster createdkubectl rollout status를 사용하여 출시되는 StatefulSet를 모니터링할 수 있습니다.- kubectl rollout status sts/es-cluster --namespace=kube-logging
클러스터가 롤아웃되면 다음 출력이 표시되어야 합니다.
OutputWaiting for 3 pods to be ready... Waiting for 2 pods to be ready... Waiting for 1 pods to be ready... partitioned roll out complete: 3 new pods have been updated...모든 포드가 배포되면 REST API에 대한 요청을 수행하여 Elasticsearch 클러스터가 올바르게 작동하는지 확인할 수 있습니다.
이렇게 하려면 먼저 로컬 포트
9200을 <를 사용하여 Elasticsearch 노드(es-cluster-0) 중 하나의 포트9200로 전달합니다. 코드>kubectl 포트 포워드:- kubectl port-forward es-cluster-0 9200:9200 --namespace=kube-logging
그런 다음 별도의 터미널 창에서 REST API에 대해
curl요청을 수행합니다.- curl http://localhost:9200/_cluster/state?pretty
다음 출력이 표시됩니다.
Output{ "cluster_name" : "k8s-logs", "compressed_size_in_bytes" : 348, "cluster_uuid" : "QD06dK7CQgids-GQZooNVw", "version" : 3, "state_uuid" : "mjNIWXAzQVuxNNOQ7xR-qg", "master_node" : "IdM5B7cUQWqFgIHXBp0JDg", "blocks" : { }, "nodes" : { "u7DoTpMmSCixOoictzHItA" : { "name" : "es-cluster-1", "ephemeral_id" : "ZlBflnXKRMC4RvEACHIVdg", "transport_address" : "10.244.8.2:9300", "attributes" : { } }, "IdM5B7cUQWqFgIHXBp0JDg" : { "name" : "es-cluster-0", "ephemeral_id" : "JTk1FDdFQuWbSFAtBxdxAQ", "transport_address" : "10.244.44.3:9300", "attributes" : { } }, "R8E7xcSUSbGbgrhAdyAKmQ" : { "name" : "es-cluster-2", "ephemeral_id" : "9wv6ke71Qqy9vk2LgJTqaA", "transport_address" : "10.244.40.4:9300", "attributes" : { } } }, ...이는 Elasticsearch 클러스터
k8s-logs가es-cluster-0,es-cluster-1, 및es-cluster-2. 현재 마스터 노드는es-cluster-0입니다.이제 Elasticsearch 클러스터가 가동되어 실행 중이므로 이에 대한 Kibana 프런트엔드 설정으로 이동할 수 있습니다.
3단계 — Kibana 배포 및 서비스 생성
Kubernetes에서 Kibana를 시작하기 위해
kibana라는 서비스와 하나의 포드 복제본으로 구성된 배포를 생성합니다. 프로덕션 요구 사항에 따라 복제본 수를 확장할 수 있으며 선택적으로 서비스에 대한LoadBalancer유형을 지정하여 배포 포드 간에 요청을 로드 밸런싱할 수 있습니다.이번에는 동일한 파일에 서비스와 배포를 생성합니다. 원하는 편집기에서
kibana.yaml파일을 엽니다.- nano kibana.yaml
다음 서비스 사양을 붙여넣습니다.
apiVersion: v1 kind: Service metadata: name: kibana namespace: kube-logging labels: app: kibana spec: ports: - port: 5601 selector: app: kibana --- apiVersion: apps/v1 kind: Deployment metadata: name: kibana namespace: kube-logging labels: app: kibana spec: replicas: 1 selector: matchLabels: app: kibana template: metadata: labels: app: kibana spec: containers: - name: kibana image: docker.elastic.co/kibana/kibana:7.2.0 resources: limits: cpu: 1000m requests: cpu: 100m env: - name: ELASTICSEARCH_URL value: http://elasticsearch:9200 ports: - containerPort: 5601그런 다음 파일을 저장하고 닫습니다.
이 사양에서는
kube-logging네임스페이스에kibana라는 서비스를 정의하고app: kibana레이블을 지정했습니다.또한 포트
5601에서 액세스할 수 있어야 하고app: kibana레이블을 사용하여 서비스의 대상 포드를 선택하도록 지정했습니다.Deployment사양에서kibana라는 배포를 정의하고 1개의 포드 복제본을 원한다고 지정합니다.우리는
docker.elastic.co/kibana/kibana:7.2.0이미지를 사용합니다. 이 시점에서 사용할 개인 또는 공용 Kibana 이미지를 대체할 수 있습니다.우리는 Pod에 최소 0.1 vCPU를 보장하고 vCPU 1개 한도까지 버스트하도록 지정합니다. 예상 로드 및 사용 가능한 리소스에 따라 이러한 매개변수를 변경할 수 있습니다.
다음으로
ELASTICSEARCH_URL환경 변수를 사용하여 Elasticsearch 클러스터의 엔드포인트와 포트를 설정합니다. Kubernetes DNS를 사용하는 이 엔드포인트는 서비스 이름elasticsearch에 해당합니다. 이 도메인은 3개의 Elasticsearch 포드에 대한 IP 주소 목록으로 확인됩니다. Kubernetes DNS에 대해 자세히 알아보려면 서비스 및 포드용 DNS를 참조하세요.마지막으로 Kibana의 컨테이너 포트를
kibana서비스가 요청을 전달할5601로 설정합니다.Kibana 구성에 만족하면
kubectl을 사용하여 서비스 및 배포를 롤아웃할 수 있습니다.- kubectl create -f kibana.yaml
다음 출력이 표시되어야 합니다.
Outputservice/kibana created deployment.apps/kibana created다음 명령을 실행하여 롤아웃이 성공했는지 확인할 수 있습니다.
- kubectl rollout status deployment/kibana --namespace=kube-logging
다음 출력이 표시되어야 합니다.
Outputdeployment "kibana" successfully rolled outKibana 인터페이스에 액세스하기 위해 다시 한 번 로컬 포트를 Kibana를 실행하는 Kubernetes 노드로 전달합니다.
kubectl get을 사용하여 Kibana 포드 세부 정보를 가져옵니다.- kubectl get pods --namespace=kube-logging
OutputNAME READY STATUS RESTARTS AGE es-cluster-0 1/1 Running 0 55m es-cluster-1 1/1 Running 0 54m es-cluster-2 1/1 Running 0 54m kibana-6c9fb4b5b7-plbg2 1/1 Running 0 4m27s여기서 우리는 Kibana 포드가
kibana-6c9fb4b5b7-plbg2라는 것을 확인합니다.로컬 포트
5601을 이 Pod의 포트5601로 전달합니다.- kubectl port-forward kibana-6c9fb4b5b7-plbg2 5601:5601 --namespace=kube-logging
다음 출력이 표시되어야 합니다.
OutputForwarding from 127.0.0.1:5601 -> 5601 Forwarding from [::1]:5601 -> 5601이제 웹 브라우저에서 다음 URL을 방문하십시오.
http://localhost:5601다음 Kibana 시작 페이지가 표시되면 Kibana를 Kubernetes 클러스터에 성공적으로 배포한 것입니다.
이제 EFK 스택의 마지막 구성 요소인 로그 수집기인 Fluentd를 롤아웃할 수 있습니다.
4단계 - Fluentd DaemonSet 만들기
이 가이드에서는 Kubernetes 클러스터의 각 노드에서 지정된 Pod의 복사본을 실행하는 Kubernetes 워크로드 유형인 DaemonSet으로 Fluentd를 설정합니다. 이 DaemonSet 컨트롤러를 사용하여 클러스터의 모든 노드에서 Fluentd 로깅 에이전트 포드를 롤아웃합니다. 이 로깅 아키텍처에 대해 자세히 알아보려면 공식 Kubernetes 문서에서 "노드 로깅 에이전트 사용\을 참조하세요.
Kubernetes에서
stdout및stderr에 로그인하는 컨테이너화된 애플리케이션은 로그 스트림을 캡처하고 노드의 JSON 파일로 리디렉션합니다. Fluentd Pod는 이러한 로그 파일을 추적하고, 로그 이벤트를 필터링하고, 로그 데이터를 변환하고, 2단계에서 배포한 Elasticsearch 로깅 백엔드로 전송합니다.컨테이너 로그 외에도 Fluentd 에이전트는 kubelet, kube-proxy 및 Docker 로그와 같은 Kubernetes 시스템 구성 요소 로그를 추적합니다. Fluentd 로깅 에이전트가 추적하는 전체 소스 목록을 보려면 공식 Kubernetes 문서에서 \노드 수준에서 로깅\을 참조하십시오.
즐겨 사용하는 텍스트 편집기에서
fluentd.yaml파일을 열어 시작합니다.- nano fluentd.yaml
다시 한 번 Kubernetes 개체 정의를 블록별로 붙여넣어 진행하면서 컨텍스트를 제공합니다. 이 가이드에서는 Kuberentes Fluentd를 사용합니다.
먼저 다음 ServiceAccount 정의를 붙여넣습니다.
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: kube-logging labels: app: fluentd여기에서 Fluentd 포드가 Kubernetes API에 액세스하는 데 사용할
fluentd라는 서비스 계정을 생성합니다.kube-logging네임스페이스에서 생성하고 다시 한 번app: fluentd레이블을 지정합니다. Kubernetes의 서비스 계정에 대해 자세히 알아보려면 공식 Kubernetes 문서에서 Pod용 서비스 계정 구성을 참조하세요.그런 다음 다음
ClusterRole블록을 붙여넣습니다.. . . --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch여기에서
fluentd라는 ClusterRole을 정의하여get,list및watch권한을 부여합니다.pods 및namespaces개체. ClusterRoles를 사용하면 노드와 같은 클러스터 범위 Kubernetes 리소스에 대한 액세스 권한을 부여할 수 있습니다. 역할 기반 액세스 제어 및 클러스터 역할에 대한 자세한 내용은 공식 Kubernetes 설명서에서 RBAC 인증 사용을 참조하세요.이제 다음
ClusterRoleBinding블록을 붙여넣습니다.. . . --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: kube-logging이 블록에서
fluentdClusterRole을fluentd서비스 계정에 바인딩하는fluentd라는ClusterRoleBinding을 정의합니다. 이렇게 하면fluentdServiceAccount에fluentd클러스터 역할에 나열된 권한이 부여됩니다.이 시점에서 실제 DaemonSet 사양에 붙여넣기를 시작할 수 있습니다.
. . . --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-logging labels: app: fluentd여기에서
kube-logging네임스페이스에fluentd라는 DaemonSet를 정의하고app: fluentd레이블을 지정합니다.그런 다음 다음 섹션에 붙여넣습니다.
. . . spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.kube-logging.svc.cluster.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable여기에서
.metadata.labels에 정의된app: fluentd레이블을 일치시킨 다음 DaemonSet에fluentd서비스 계정을 할당합니다. 또한 이 DaemonSet에서 관리하는 포드로app: fluentd를 선택합니다.다음으로, Kubernetes 마스터 노드에서 동등한 taint와 일치하도록
NoSchedule내결함성을 정의합니다. 이렇게 하면 DaemonSet도 Kubernetes 마스터로 롤아웃됩니다. 마스터 노드에서 Fluentd 포드를 실행하지 않으려면 이 내결함성을 제거하십시오. Kubernetes taint 및 tolerations에 대해 자세히 알아보려면 공식 Kubernetes 문서에서 "Taints and Tolerations\를 참조하십시오.다음으로
fluentd라고 하는 포드 컨테이너 정의를 시작합니다.우리는 fluentd-kubernetes-daemonset Github 저장소를 사용합니다.
다음으로 몇 가지 환경 변수를 사용하여 Fluentd를 구성합니다.
FLUENT_ELASTICSEARCH_HOST: 앞에서 정의한 Elasticsearch 헤드리스 서비스 주소(elasticsearch.kube-logging.svc.cluster.local)로 설정했습니다. 이는 3개의 Elasticsearch 포드에 대한 IP 주소 목록으로 확인됩니다. 실제 Elasticsearch 호스트는 이 목록에서 반환된 첫 번째 IP 주소일 가능성이 큽니다. 클러스터 전체에 로그를 배포하려면 Fluentd의 Elasticsearch 출력 플러그인에 대한 구성을 수정해야 합니다. 이 플러그인에 대해 자세히 알아보려면 Elasticsearch 출력 플러그인을 참조하세요.FLUENT_ELASTICSEARCH_PORT: 이전에 구성한 Elasticsearch 포트인9200으로 설정했습니다.FLUENT_ELASTICSEARCH_SCHEME:http로 설정했습니다.FLUENTD_SYSTEMD_CONF:disable로 설정하여 컨테이너에 설정되지 않은systemd와 관련된 출력을 억제합니다.
마지막으로 다음 섹션에 붙여넣습니다.
. . . resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containers여기서는 FluentD Pod에 대해 512MiB 메모리 제한을 지정하고 0.1vCPU 및 200MiB 메모리를 보장합니다. 예상 로그 볼륨 및 사용 가능한 리소스에 따라 이러한 리소스 제한 및 요청을 조정할 수 있습니다.
다음으로
varlog및/var/lib/docker/containers호스트 경로를varlog및를 사용하여 컨테이너에 마운트합니다. >varlibdockercontainersvolumeMounts. 이러한볼륨은 블록의 끝에서 정의됩니다.이 블록에서 정의하는 마지막 매개변수는
terminationGracePeriodSeconds로,SIGTERM신호를 수신하면 Fluentd가 정상적으로 종료할 수 있도록 30초를 제공합니다. 30초 후 컨테이너에SIGKILL신호가 전송됩니다.terminationGracePeriodSeconds의 기본값은 30초이므로 대부분의 경우 이 매개변수를 생략할 수 있습니다. Kubernetes 워크로드를 정상적으로 종료하는 방법에 대해 자세히 알아보려면 Google의 "Kubernetes 모범 사례: 정상적으로 종료\를 참조하세요.전체 Fluentd 사양은 다음과 같아야 합니다.
apiVersion: v1 kind: ServiceAccount metadata: name: fluentd namespace: kube-logging labels: app: fluentd --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: fluentd labels: app: fluentd rules: - apiGroups: - "" resources: - pods - namespaces verbs: - get - list - watch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: fluentd roleRef: kind: ClusterRole name: fluentd apiGroup: rbac.authorization.k8s.io subjects: - kind: ServiceAccount name: fluentd namespace: kube-logging --- apiVersion: apps/v1 kind: DaemonSet metadata: name: fluentd namespace: kube-logging labels: app: fluentd spec: selector: matchLabels: app: fluentd template: metadata: labels: app: fluentd spec: serviceAccount: fluentd serviceAccountName: fluentd tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule containers: - name: fluentd image: fluent/fluentd-kubernetes-daemonset:v1.4.2-debian-elasticsearch-1.1 env: - name: FLUENT_ELASTICSEARCH_HOST value: "elasticsearch.kube-logging.svc.cluster.local" - name: FLUENT_ELASTICSEARCH_PORT value: "9200" - name: FLUENT_ELASTICSEARCH_SCHEME value: "http" - name: FLUENTD_SYSTEMD_CONF value: disable resources: limits: memory: 512Mi requests: cpu: 100m memory: 200Mi volumeMounts: - name: varlog mountPath: /var/log - name: varlibdockercontainers mountPath: /var/lib/docker/containers readOnly: true terminationGracePeriodSeconds: 30 volumes: - name: varlog hostPath: path: /var/log - name: varlibdockercontainers hostPath: path: /var/lib/docker/containersFluentd DaemonSet 구성을 마쳤으면 파일을 저장하고 닫습니다.
이제
kubectl을 사용하여 DaemonSet를 롤아웃합니다.- kubectl create -f fluentd.yaml
다음 출력이 표시되어야 합니다.
Outputserviceaccount/fluentd created clusterrole.rbac.authorization.k8s.io/fluentd created clusterrolebinding.rbac.authorization.k8s.io/fluentd created daemonset.extensions/fluentd createdkubectl을 사용하여 DaemonSet가 성공적으로 롤아웃되었는지 확인합니다.- kubectl get ds --namespace=kube-logging
다음 상태 출력이 표시되어야 합니다.
OutputNAME DESIRED CURRENT READY UP-TO-DATE AVAILABLE NODE SELECTOR AGE fluentd 3 3 3 3 3 <none> 58s이는 Kubernetes 클러스터의 노드 수에 해당하는 3개의
fluentd포드가 실행 중임을 나타냅니다.이제 Kibana를 확인하여 로그 데이터가 올바르게 수집되고 Elasticsearch로 전달되는지 확인할 수 있습니다.
kubectl port-forward가 열린 상태에서http://localhost:5601로 이동합니다.왼쪽 탐색 메뉴에서 검색을 클릭합니다.
다음 구성 창이 표시됩니다.

이를 통해 Kibana에서 탐색하려는 Elasticsearch 인덱스를 정의할 수 있습니다. 자세한 내용은 공식 Kibana 문서에서 인덱스 패턴 정의를 참조하세요. 지금은
logstash-*와일드카드 패턴을 사용하여 Elasticsearch 클러스터의 모든 로그 데이터를 캡처합니다. 텍스트 상자에logstash-*를 입력하고 다음 단계를 클릭합니다.그러면 다음 페이지로 이동합니다.
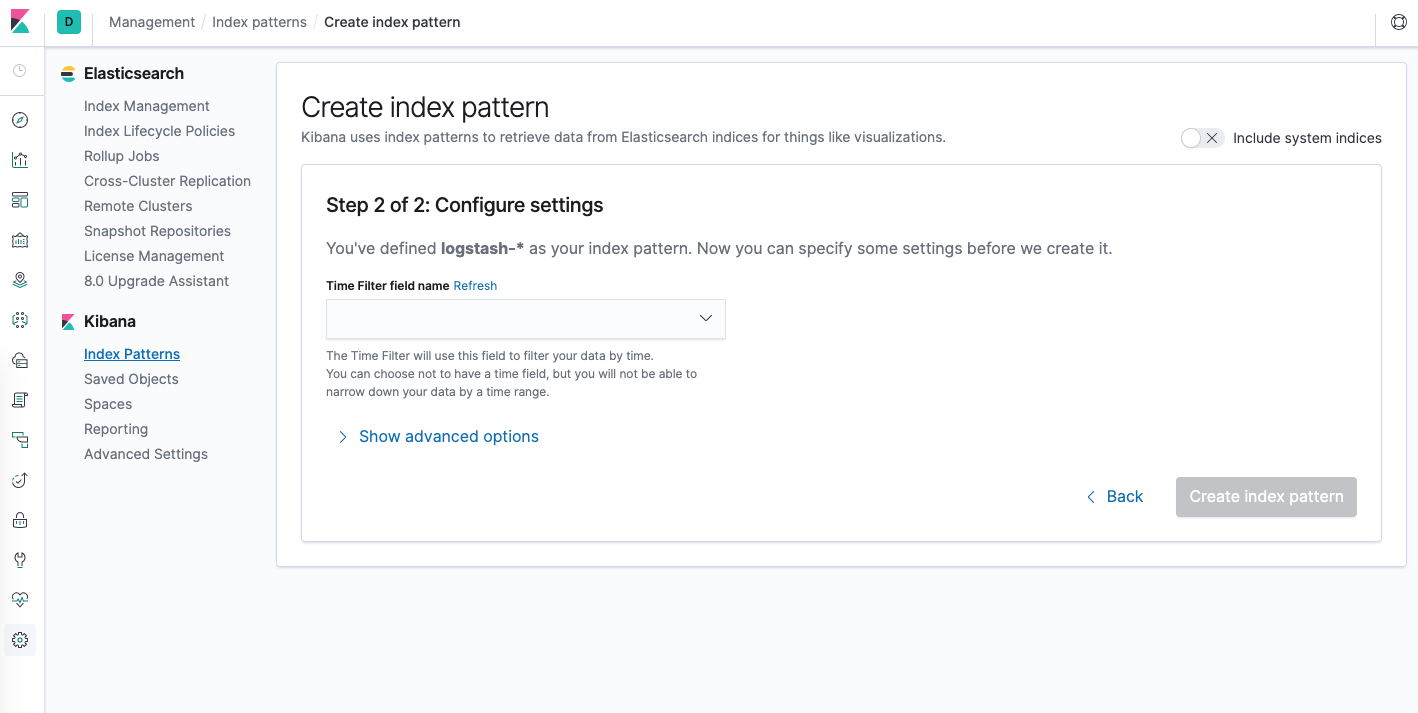
이를 통해 Kibana가 시간별로 로그 데이터를 필터링하는 데 사용할 필드를 구성할 수 있습니다. 드롭다운에서 @timestamp 필드를 선택하고 인덱스 패턴 생성을 누르십시오.
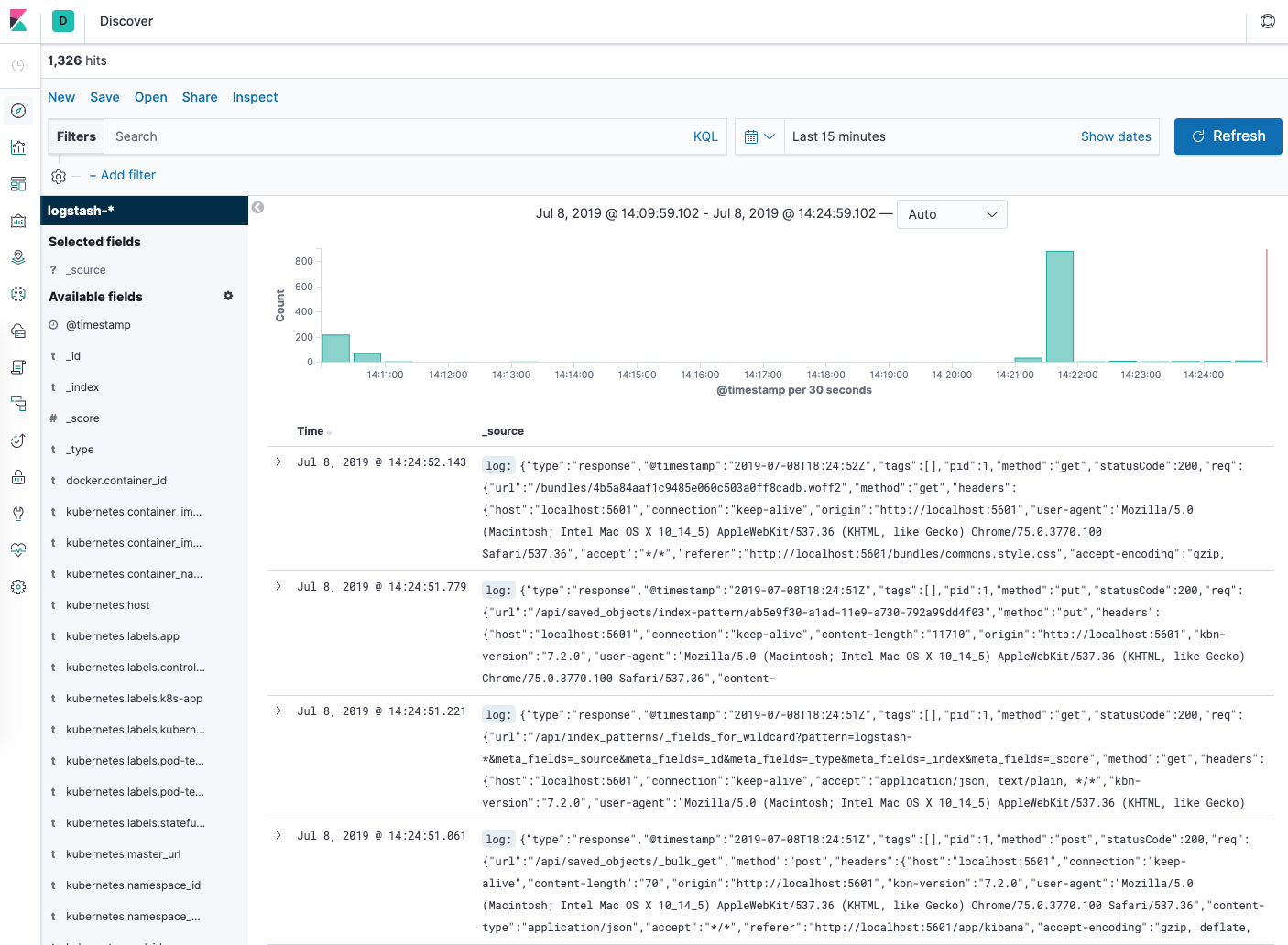
이제 왼쪽 탐색 메뉴에서 검색을 누르십시오.
히스토그램 그래프와 일부 최근 로그 항목이 표시됩니다.
이제 Kubernetes 클러스터에서 EFK 스택을 성공적으로 구성하고 롤아웃했습니다. Kibana를 사용하여 로그 데이터를 분석하는 방법을 알아보려면 Kibana 사용 설명서를 참조하십시오.
다음 옵션 섹션에서는 stdout에 숫자를 출력하고 Kibana에서 해당 로그를 찾는 간단한 카운터 Pod를 배포합니다.
5단계(선택 사항) - 컨테이너 로깅 테스트
주어진 포드에 대한 최신 로그를 탐색하는 기본 Kibana 사용 사례를 시연하기 위해 순차 번호를 stdout에 출력하는 최소 카운터 포드를 배포합니다.
포드를 생성하는 것부터 시작하겠습니다. 원하는 편집기에서
counter.yaml파일을 엽니다.- nano counter.yaml
그런 다음 다음 Pod 사양을 붙여넣습니다.
apiVersion: v1 kind: Pod metadata: name: counter spec: containers: - name: count image: busybox args: [/bin/sh, -c, 'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']파일을 저장하고 닫습니다.
이것은 숫자를 순차적으로 출력하는
while루프를 실행하는counter라는 최소 Pod입니다.kubectl을 사용하여카운터포드를 배포합니다.- kubectl create -f counter.yaml
Pod가 생성되고 실행되면 Kibana 대시보드로 다시 이동합니다.
검색 페이지에서 검색 표시줄에
kubernetes.pod_name:counter를 입력합니다. 이렇게 하면 이름이counter인 Pod의 로그 데이터가 필터링됩니다.그러면
counter포드에 대한 로그 항목 목록이 표시됩니다.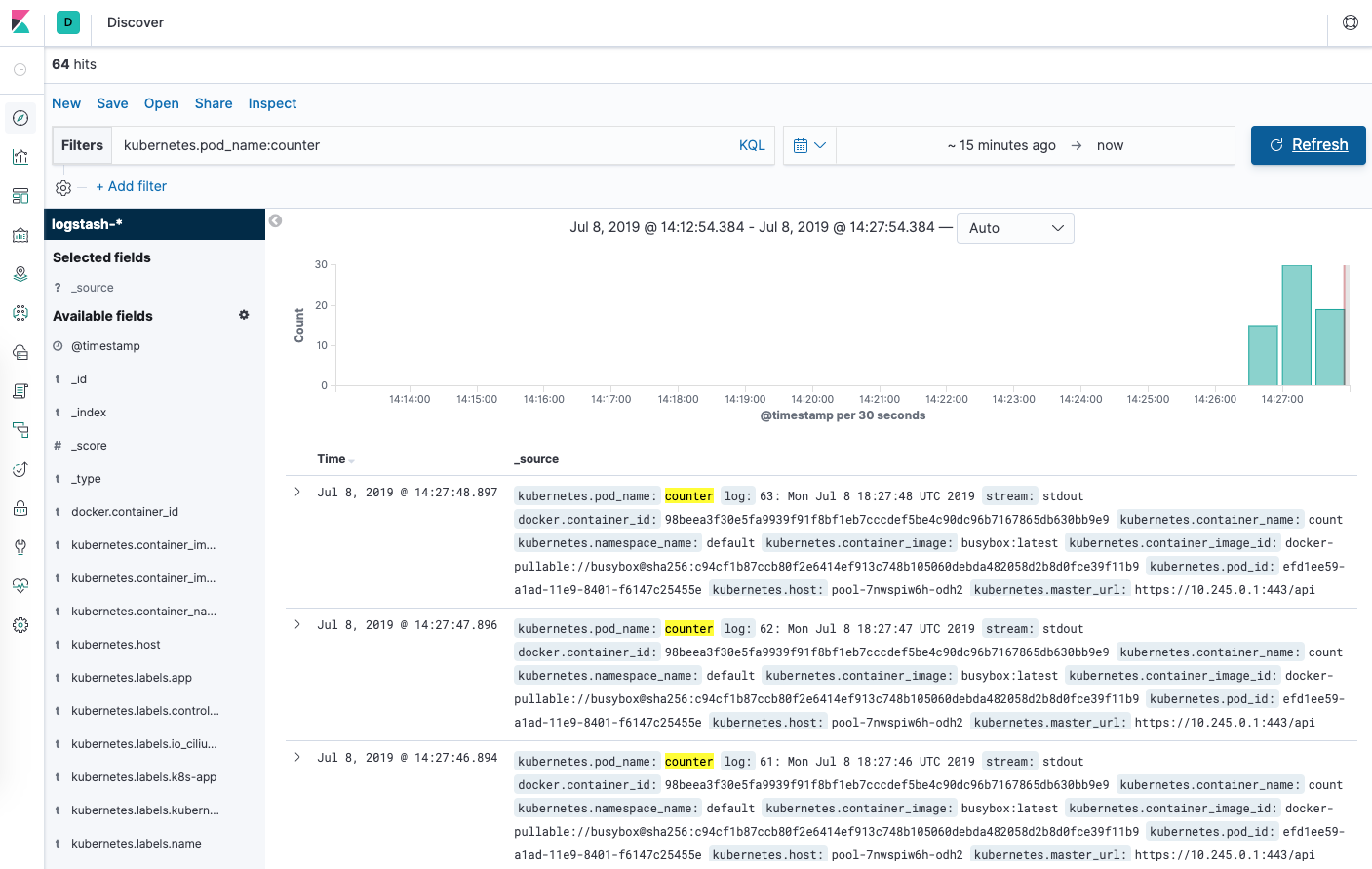
로그 항목을 클릭하면 컨테이너 이름, Kubernetes 노드, 네임스페이스 등과 같은 추가 메타데이터를 볼 수 있습니다.
결론
이 가이드에서는 Kubernetes 클러스터에서 Elasticsearch, Fluentd 및 Kibana를 설정하고 구성하는 방법을 시연했습니다. 각 Kubernetes 작업자 노드에서 실행되는 단일 로깅 에이전트 Pod로 구성된 최소 로깅 아키텍처를 사용했습니다.
이 로깅 스택을 프로덕션 Kubernetes 클러스터에 배포하기 전에 이 가이드 전체에 표시된 대로 리소스 요구 사항 및 제한을 조정하는 것이 가장 좋습니다. 내장된 모니터링 및 보안 기능을 활성화하도록 X-Pack을 설정할 수도 있습니다.
여기에서 사용한 로깅 아키텍처는 3개의 Elasticsearch 포드, 단일 Kibana 포드(로드 밸런싱되지 않음) 및 DaemonSet으로 출시된 Fluentd 포드 세트로 구성됩니다. 프로덕션 사용 사례에 따라 이 설정을 확장할 수 있습니다. Elasticsearch 및 Kibana 스택 확장에 대해 자세히 알아보려면 Scaling Elasticsearch를 참조하십시오.
Kubernetes는 또한 사용 사례에 더 적합할 수 있는 더 복잡한 로깅 에이전트 아키텍처를 허용합니다. 자세히 알아보려면 Kubernetes 문서에서 로깅 아키텍처를 참조하세요.