Scikit-learn을 사용하여 Python에서 기계 학습 분류자를 구축하는 방법
소개
기계 학습은 컴퓨터 과학, 인공 지능 및 통계의 연구 분야입니다. 기계 학습의 초점은 알고리즘을 훈련하여 패턴을 학습하고 데이터에서 예측하는 것입니다. 기계 학습은 컴퓨터를 사용하여 의사 결정 프로세스를 자동화할 수 있기 때문에 특히 가치가 있습니다.
어디에서나 기계 학습 애플리케이션을 찾을 수 있습니다. Netflix와 Amazon은 기계 학습을 사용하여 신제품을 추천합니다. 은행은 기계 학습을 사용하여 신용 카드 거래에서 사기 행위를 탐지하고 의료 회사는 기계 학습을 사용하여 환자를 모니터링, 평가 및 진단하기 시작했습니다.
이 자습서에서는 종양이 악성인지 양성인지 예측하는 Naive Bayes(NB) 분류기를 사용하여 Python에서 간단한 기계 학습 알고리즘을 구현합니다.
이 자습서를 마치면 Python에서 고유한 기계 학습 모델을 빌드하는 방법을 알게 됩니다.
전제 조건
이 자습서를 완료하려면 다음이 필요합니다.
- Python 3 및 컴퓨터에 설치된 로컬 프로그래밍 환경. 운영 체제에 대한 적절한 설치 및 설정 가이드에 따라 이를 구성할 수 있습니다.\n
- Python을 처음 사용하는 경우 Python 3에서 코딩하는 방법을 탐색하여 언어에 익숙해질 수 있습니다.
1단계 - Scikit-learn 가져오기
Python을 위한 가장 훌륭하고 문서화된 기계 학습 라이브러리 중 하나인 Python 모듈 Scikit-learn을 설치하는 것으로 시작하겠습니다.
코딩 프로젝트를 시작하기 위해 Python 3 프로그래밍 환경을 활성화해 보겠습니다. 환경이 있는 디렉터리에 있는지 확인하고 다음 명령을 실행합니다.
- . my_env/bin/activate
프로그래밍 환경이 활성화된 상태에서 Sckikit-learn 모듈이 이미 설치되어 있는지 확인하십시오.
- python -c "import sklearn"
sklearn이 설치된 경우 이 명령은 오류 없이 완료됩니다. 설치되지 않은 경우 다음과 같은 오류 메시지가 표시됩니다.OutputTraceback (most recent call last): File "<string>", line 1, in <module> ImportError: No module named 'sklearn'오류 메시지는
sklearn이 설치되지 않았음을 나타내므로pip를 사용하여 라이브러리를 다운로드합니다.- pip install scikit-learn[alldeps]
설치가 완료되면 Jupyter Notebook을 시작합니다.
- jupyter notebook
Jupyter에서 ML Tutorial이라는 새 Python Notebook을 만듭니다. Notebook의 첫 번째 셀에서
sklearn모듈을 가져옵니다.import sklearn노트북은 다음 그림과 같아야 합니다.

이제 노트북에
sklearn을 가져왔으므로 기계 학습 모델용 데이터 세트 작업을 시작할 수 있습니다.2단계 - Scikit-learn의 데이터 세트 가져오기
이 튜토리얼에서 작업할 데이터 세트는 Breast Cancer Wisconsin Diagnostic Database입니다. 이 데이터 세트에는 유방암 종양에 대한 다양한 정보와 악성 또는 양성 분류 레이블이 포함되어 있습니다. 데이터 세트에는 569개의 종양에 대한 569개의 인스턴스 또는 데이터가 있으며 30개의 속성에 대한 정보 또는 종양의 반경, 질감, 평활도 및 면적과 같은 기능이 포함되어 있습니다. .
이 데이터 세트를 사용하여 종양 정보를 사용하여 종양이 악성인지 양성인지 예측하는 기계 학습 모델을 구축합니다.
Scikit-learn은 Python에 로드할 수 있는 다양한 데이터 세트와 함께 설치되어 있으며 원하는 데이터 세트가 포함되어 있습니다. 데이터세트 가져오기 및 로드:
... from sklearn.datasets import load_breast_cancer # Load dataset data = load_breast_cancer()데이터사전입니다. 고려해야 할 중요한 사전 키는 분류 레이블 이름(target_names), 실제 레이블(target), 속성/기능 이름(feature_names)입니다. ), 속성(데이터).속성은 모든 분류기의 중요한 부분입니다. 속성은 데이터의 특성에 대한 중요한 특성을 캡처합니다. 예측하려는 레이블(악성 종양 대 양성 종양)이 주어지면 가능한 유용한 속성에는 종양의 크기, 반경 및 질감이 포함됩니다.
각각의 중요한 정보 집합에 대해 새 변수를 만들고 데이터를 할당합니다.
... # Organize our data label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data']이제 각 정보 집합에 대한 목록이 있습니다. 데이터 세트를 더 잘 이해하기 위해 클래스 레이블, 첫 번째 데이터 인스턴스의 레이블, 기능 이름 및 첫 번째 데이터 인스턴스의 기능 값을 인쇄하여 데이터를 살펴보겠습니다.
... # Look at our data print(label_names) print(labels[0]) print(feature_names[0]) print(features[0])코드를 실행하면 다음과 같은 결과가 표시됩니다.
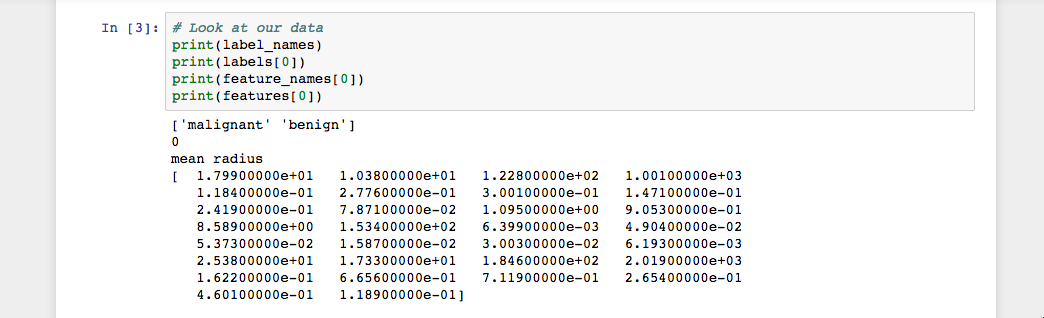
이미지에서 볼 수 있듯이 클래스 이름은 악성 및 양성이며
0및1의 이진 값으로 매핑됩니다. 여기서0은 악성을 나타냅니다. 종양 및1은 양성 종양을 나타냅니다. 따라서 첫 번째 데이터 인스턴스는 평균 반경이1.79900000e+01인 악성 종양입니다.이제 데이터를 로드했으므로 데이터를 사용하여 기계 학습 분류기를 구축할 수 있습니다.
3단계 - 데이터를 집합으로 구성
분류기가 얼마나 잘 수행되고 있는지 평가하려면 항상 본 적이 없는 데이터에서 모델을 테스트해야 합니다. 따라서 모델을 구축하기 전에 데이터를 훈련 세트와 테스트 세트의 두 부분으로 나눕니다.
훈련 세트를 사용하여 개발 단계에서 모델을 훈련하고 평가합니다. 그런 다음 훈련된 모델을 사용하여 보이지 않는 테스트 세트에 대한 예측을 수행합니다. 이 접근 방식을 통해 모델의 성능과 견고성을 알 수 있습니다.
다행히
sklearn에는train_test_split()이라는 함수가 있어 데이터를 이러한 집합으로 나눕니다. 함수를 가져온 다음 이를 사용하여 데이터를 분할합니다.... from sklearn.model_selection import train_test_split # Split our data train, test, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=42)이 함수는
test_size매개변수를 사용하여 데이터를 무작위로 분할합니다. 이 예에서는 원본 데이터 세트의 33%를 나타내는 테스트 세트(test)가 있습니다. 나머지 데이터(train)는 학습 데이터를 구성합니다. 또한 학습/테스트 변수에 대한 각각의 레이블(예:train_labels및test_labels)이 있습니다.이제 첫 번째 모델 훈련으로 넘어갈 수 있습니다.
4단계 - 모델 구축 및 평가
기계 학습에는 많은 모델이 있으며 각 모델에는 고유한 강점과 약점이 있습니다. 이 자습서에서는 이진 분류 작업, 즉 Naive Bayes(NB)에서 일반적으로 잘 수행되는 간단한 알고리즘에 중점을 둘 것입니다.
먼저
GaussianNB모듈을 가져옵니다. 그런 다음GaussianNB()함수로 모델을 초기화한 다음gnb.fit()을 사용하여 데이터에 피팅하여 모델을 훈련합니다.... from sklearn.naive_bayes import GaussianNB # Initialize our classifier gnb = GaussianNB() # Train our classifier model = gnb.fit(train, train_labels)모델을 학습한 후 학습된 모델을 사용하여
predict()함수를 사용하여 테스트 세트에 대한 예측을 수행할 수 있습니다.predict()함수는 테스트 세트의 각 데이터 인스턴스에 대한 예측 배열을 반환합니다. 그런 다음 모델이 결정한 내용을 이해하기 위해 예측을 인쇄할 수 있습니다.test세트와 함께predict()함수를 사용하고 결과를 인쇄하십시오.... # Make predictions preds = gnb.predict(test) print(preds)코드를 실행하면 다음과 같은 결과가 표시됩니다.
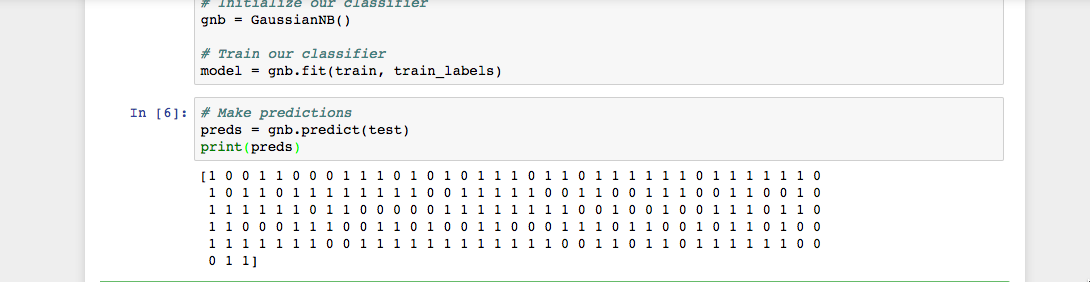
Jupyter Notebook 출력에서 볼 수 있듯이
predict()함수는 다음에 대한 예측 값을 나타내는0및1의 배열을 반환했습니다. 종양 등급(악성 대 양성).이제 예측을 마쳤으니 분류기가 얼마나 잘 수행되고 있는지 평가해 보겠습니다.
5단계 - 모델의 정확도 평가
실제 클래스 레이블 배열을 사용하여 두 배열(
test_labels대preds)을 비교하여 모델의 예측 값의 정확도를 평가할 수 있습니다. 기계 학습 분류기의 정확도를 결정하기 위해sklearn함수accuracy_score()를 사용할 것입니다.... from sklearn.metrics import accuracy_score # Evaluate accuracy print(accuracy_score(test_labels, preds))다음과 같은 결과가 표시됩니다.

출력에서 볼 수 있듯이 NB 분류기는 94.15% 정확합니다. 이것은 분류기가 종양이 악성인지 양성인지에 대해 정확한 예측을 할 수 있는 시간의 94.15%를 의미합니다. 이러한 결과는 30가지 속성의 기능 세트가 종양 클래스의 좋은 지표임을 시사합니다.
첫 번째 기계 학습 분류기를 성공적으로 구축했습니다. 모든
import문을 Notebook 또는 스크립트의 맨 위에 배치하여 코드를 재구성해 보겠습니다. 코드의 최종 버전은 다음과 같아야 합니다.from sklearn.datasets import load_breast_cancer from sklearn.model_selection import train_test_split from sklearn.naive_bayes import GaussianNB from sklearn.metrics import accuracy_score # Load dataset data = load_breast_cancer() # Organize our data label_names = data['target_names'] labels = data['target'] feature_names = data['feature_names'] features = data['data'] # Look at our data print(label_names) print('Class label = ', labels[0]) print(feature_names) print(features[0]) # Split our data train, test, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=42) # Initialize our classifier gnb = GaussianNB() # Train our classifier model = gnb.fit(train, train_labels) # Make predictions preds = gnb.predict(test) print(preds) # Evaluate accuracy print(accuracy_score(test_labels, preds))이제 코드 작업을 계속하여 분류기의 성능을 더욱 향상시킬 수 있는지 확인할 수 있습니다. 기능의 다른 하위 집합으로 실험하거나 완전히 다른 알고리즘을 시도할 수도 있습니다. 더 많은 기계 학습 아이디어는 Scikit-learn의 웹사이트를 확인하세요.
결론
이 자습서에서는 Python에서 기계 학습 분류자를 빌드하는 방법을 배웠습니다. 이제 Scikit-learn을 사용하여 Python에서 데이터를 로드하고, 데이터를 구성하고, 기계 학습 분류자를 학습, 예측 및 평가할 수 있습니다. 이 자습서의 단계는 Python에서 자신의 데이터로 작업하는 프로세스를 용이하게 하는 데 도움이 됩니다.