Debian 11에 Apache Spark를 설치하는 방법
이 튜토리얼은 다음 OS 버전에 대해 존재합니다.
- 데비안 11(불스아이)
- 데비안 10(버스터)
이 페이지에서
- 전제 조건
- 자바 설치
- Apache Spark 설치
- Apache Spark 시작
- Apache Spark 웹 UI에 액세스
- 명령줄을 통해 Apache Spark 연결\n
- 마스터와 슬레이브 중지
- 결론
Apache Spark는 더 빠른 계산 결과를 제공하기 위해 만들어진 무료 오픈 소스 범용 분산 계산 프레임워크입니다. Java, Python, Scala 및 R을 포함한 스트리밍, 그래프 처리를 위한 여러 API를 지원합니다. 일반적으로 Apache Spark는 Hadoop 클러스터에서 사용할 수 있지만 독립 실행형 모드로 설치할 수도 있습니다.
이 튜토리얼에서는 Debian 11에 Apache Spark 프레임워크를 설치하는 방법을 보여줍니다.
전제 조건
- Debian 11을 실행하는 서버.\n
- 루트 암호는 서버에서 구성됩니다.\n
자바 설치
Apache Spark는 Java로 작성되었습니다. 따라서 시스템에 Java가 설치되어 있어야 합니다. 설치되어 있지 않은 경우 다음 명령을 사용하여 설치할 수 있습니다.
apt-get install default-jdk curl -y
Java가 설치되면 다음 명령을 사용하여 Java 버전을 확인합니다.
java --version
다음 출력이 표시되어야 합니다.
openjdk 11.0.12 2021-07-20 OpenJDK Runtime Environment (build 11.0.12+7-post-Debian-2) OpenJDK 64-Bit Server VM (build 11.0.12+7-post-Debian-2, mixed mode, sharing)
아파치 스파크 설치
이 자습서를 작성할 당시 Apache Spark의 최신 버전은 3.1.2입니다. 다음 명령을 사용하여 다운로드할 수 있습니다.
wget https://dlcdn.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
다운로드가 완료되면 다음 명령을 사용하여 다운로드한 파일의 압축을 풉니다.
tar -xvzf spark-3.1.2-bin-hadoop3.2.tgz
그런 다음 다음 명령을 사용하여 추출된 디렉터리를 /opt로 이동합니다.
mv spark-3.1.2-bin-hadoop3.2/ /opt/spark
다음으로 ~/.bashrc 파일을 편집하고 Spark 경로 변수를 추가합니다.
nano ~/.bashrc
다음 줄을 추가합니다.
export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
파일을 저장하고 닫은 후 다음 명령을 사용하여 Spark 환경 변수를 활성화합니다.
source ~/.bashrc
아파치 스파크 시작
이제 다음 명령을 실행하여 Spark 마스터 서비스를 시작할 수 있습니다.
start-master.sh
다음 출력이 표시되어야 합니다.
starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-root-org.apache.spark.deploy.master.Master-1-debian11.out
기본적으로 Apache Spark는 포트 8080에서 수신합니다. 다음 명령을 사용하여 확인할 수 있습니다.
ss -tunelp | grep 8080
다음과 같은 결과가 표시됩니다.
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=24356,fd=296)) ino:47523 sk:b cgroup:/user.slice/user-0.slice/session-1.scope v6only:0 <->
다음으로 다음 명령을 사용하여 Apache Spark 작업자 프로세스를 시작합니다.
start-slave.sh spark://your-server-ip:7077
Apache Spark 웹 UI에 액세스
이제 URL http://your-server-ip:8080을 사용하여 Apache Spark 웹 인터페이스에 액세스할 수 있습니다. 다음 화면에 Apache Spark 마스터 및 슬레이브 서비스가 표시되어야 합니다.
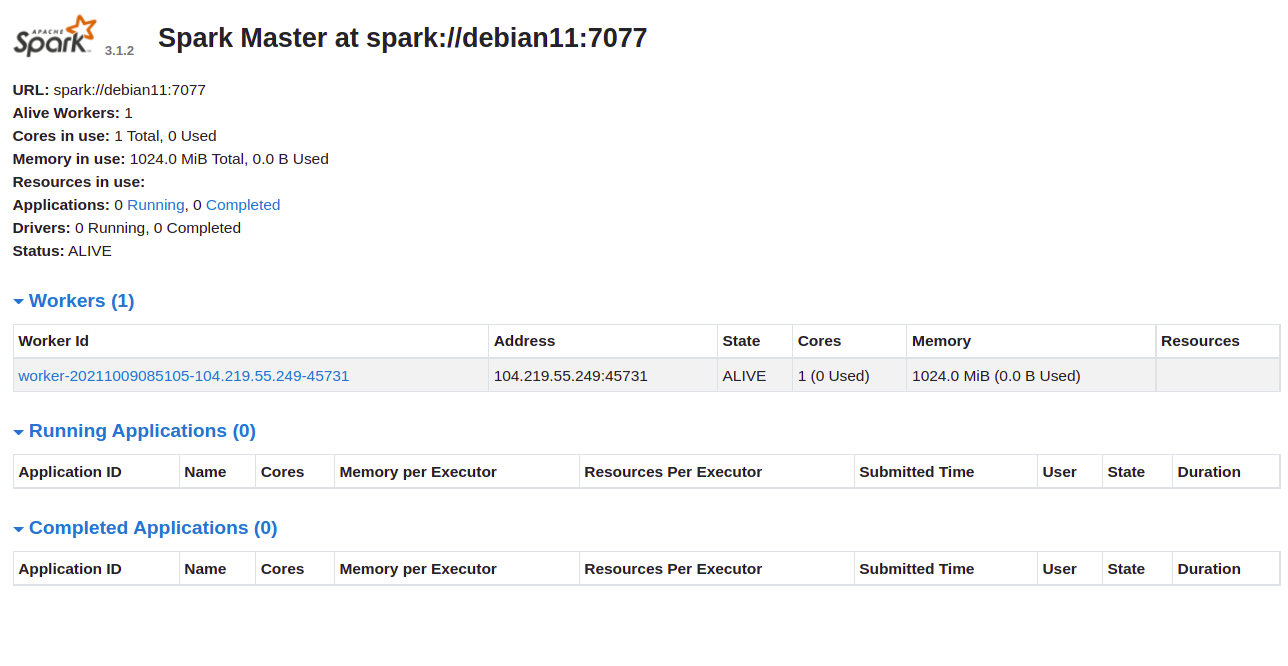
작업자 ID를 클릭합니다. 다음 화면에서 작업자의 자세한 정보를 볼 수 있습니다.

명령줄을 통해 Apache Spark 연결
명령 셸을 통해 Spark에 연결하려면 아래 명령을 실행합니다.
spark-shell
연결되면 다음과 같은 인터페이스가 표시됩니다.
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Scala version 2.12.10 (OpenJDK 64-Bit Server VM, Java 11.0.12)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Spark에서 Python을 사용하려는 경우. pyspark 명령줄 유틸리티를 사용할 수 있습니다.
먼저 다음 명령을 사용하여 Python 버전 2를 설치합니다.
apt-get install python -y
설치가 완료되면 다음 명령을 사용하여 Spark를 연결할 수 있습니다.
pyspark
연결되면 다음과 같은 결과가 표시됩니다.
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/__ / .__/\_,_/_/ /_/\_\ version 3.1.2
/_/
Using Python version 3.9.2 (default, Feb 28 2021 17:03:44)
Spark context Web UI available at http://debian11:4040
Spark context available as 'sc' (master = local[*], app id = local-1633769632964).
SparkSession available as 'spark'.
>>>
마스터와 슬레이브 중지
먼저 다음 명령을 사용하여 슬레이브 프로세스를 중지합니다.
stop-slave.sh
다음과 같은 결과가 표시됩니다.
stopping org.apache.spark.deploy.worker.Worker
그런 다음 다음 명령을 사용하여 마스터 프로세스를 중지합니다.
stop-master.sh
다음과 같은 결과가 표시됩니다.
stopping org.apache.spark.deploy.master.Master
결론
축하합니다! Debian 11에 Apache Spark를 성공적으로 설치했습니다. 이제 조직에서 Apache Spark를 사용하여 대규모 데이터 세트를 처리할 수 있습니다.