Linux에서 유용한 egrep 명령 예제 20개
요약: 이 가이드에서는 egrep 명령의 몇 가지 실제 예를 논의합니다. 이 가이드를 따르면 사용자는 Linux에서 텍스트 검색을 보다 효율적으로 수행할 수 있습니다.
로그에서 필요한 정보를 찾을 수 없어 답답했던 적이 있나요? 대규모 데이터 세트에서 필요한 정보를 추출하는 것은 복잡하고 시간이 많이 걸리는 작업입니다.
운영 체제가 올바른 도구를 제공하지 않으면 상황이 정말 어려워지고 여기에 Linux가 여러분을 구해줄 것입니다. Linux는 awk, sed, cut 등과 같은 다양한 텍스트 필터링 유틸리티를 제공합니다.
그러나 egrep은 Linux에서 텍스트 처리를 위해 가장 강력하고 일반적으로 사용되는 유틸리티 중 하나이며 egrep 명령의 몇 가지 예를 논의하겠습니다.
Linux의 egrep 명령은 파일의 특정 패턴을 검색하고 일치시키는 데 사용되는 grep 명령 계열로 인식됩니다. grep -E(grep Extended regex)와 유사하게 작동하지만 대부분 특정 파일 또는 줄 단위로 검색하거나 지정된 파일의 줄을 인쇄합니다.
egrep 명령의 구문은 다음과 같습니다.
egrep [OPTIONS] PATTERNS [FILES]
예제를 사용하기 위해 다음 내용으로 샘플 텍스트 파일을 만들어 보겠습니다.
cat sample.txt

여기서 텍스트 파일이 준비된 것을 볼 수 있습니다. 이제 일상적으로 사용할 수 있는 몇 가지 일반적인 예를 살펴보겠습니다.
1. 단일 파일에서 패턴을 찾는 방법
간단한 패턴 일치 예제부터 시작하겠습니다. 아래 명령을 사용하여 sample.txt 파일에서 professional 문자열을 검색할 수 있습니다.
egrep professionals sample.txt

여기서는 명령이 지정된 패턴을 포함하는 줄을 인쇄하는 것을 볼 수 있습니다.
2. 파일에서 일치하는 패턴을 강조하는 방법
일치하는 패턴을 강조 표시하여 출력에서 더 많은 정보를 얻을 수 있습니다. 이를 달성하기 위해 egrep 명령의 --color 옵션을 사용할 수 있습니다. 예를 들어, 아래 명령은 professionals 텍스트를 빨간색으로 강조 표시합니다.
egrep --color=auto professionals sample.txt

여기서는 동일한 출력이 이전 출력에 비해 더 많은 정보를 제공한다는 것을 알 수 있습니다. 또한 professionals라는 단어가 두 번 반복되는 것을 쉽게 확인할 수 있습니다.
대부분의 Linux 시스템에서 위 설정은 다음 별칭을 사용하여 기본적으로 활성화됩니다.
alias egrep='egrep –color=auto'
3. 여러 파일에서 패턴을 찾는 방법
egrep 명령은 여러 파일을 인수로 허용하므로 여러 파일에서 특정 패턴을 검색할 수 있습니다. 예를 들어 이것을 이해해 봅시다.
먼저 sample.txt 파일의 복사본을 만듭니다.
cp sample.txt sample-copy.txt
이제 두 파일 모두에서 professionals 패턴을 검색하세요.
egrep professionals sample.txt sample-copy.txt

위의 예에서는 해당 파일에서 일치하는 줄을 나타내는 출력에서 파일 이름을 볼 수 있습니다.
4. 파일에서 일치하는 줄 수를 계산하는 방법
때로는 패턴이 파일에 존재하는지 여부만 알아내면 됩니다. 그렇다면 현재 몇 줄에 있습니까? 이러한 경우 명령의 -c 옵션을 사용할 수 있습니다.
예를 들어, 아래 명령은 professionals라는 단어가 한 줄에만 있기 때문에 출력으로 1을 표시합니다.
egrep -c professionals sample.txt
1
5. 파일에서 일치하는 줄만 인쇄하는 방법
이전 예에서는 -c 옵션이 패턴 발생 횟수를 계산하지 않는 것을 확인했습니다. 예를 들어, professionals라는 단어가 같은 줄에 두 번 나타나지만 -c 옵션은 이를 단일 일치 항목으로만 처리합니다.
이러한 경우 명령의 -o 옵션을 사용하여 일치하는 패턴만 인쇄할 수 있습니다. 예를 들어, 아래 명령은 professionals라는 단어를 별도의 두 줄에 표시합니다.
egrep -o professionals sample.txt
이제 wc 명령을 사용하여 줄 수를 세어 보겠습니다.
egrep -o professionals sample.txt | wc -l

위의 예에서는 egrep 및 wc 명령의 조합을 사용하여 특정 패턴의 발생 횟수를 계산했습니다.
6. 대소문자를 무시하여 패턴을 찾는 방법
기본적으로 egrep은 대소문자를 구분하여 패턴 일치를 수행합니다. 단어를 의미합니다. we, We, wE, WE는 서로 다른 단어로 취급됩니다. 그러나 -i 옵션을 사용하면 대소문자를 구분하지 않고 검색할 수 있습니다.
예를 들어 아래 명령에서 we 및 We 텍스트에 대한 패턴 일치가 성공합니다.
egrep -i we sample.txt

7. 부분적으로 일치하는 패턴을 제외하는 방법
이전 예에서는 egrep 명령이 부분 일치를 수행하는 것을 확인했습니다. 예를 들어 we 텍스트를 검색하면 다른 텍스트에서도 패턴 일치가 성공했습니다. 웹, 웹사이트 등이 있습니다.
이러한 제한을 극복하기 위해 전체 단어 일치를 강제하는 -w 옵션을 사용할 수 있습니다.
egrep -w we sample.txt

8. 파일에서 패턴 매칭을 반전시키는 방법
지금까지 우리는 egrep 명령을 사용하여 주어진 패턴이 있는 줄을 인쇄했습니다. 그러나 때로는 반대 방식으로 작업을 수행하고 싶을 때도 있습니다.
예를 들어, 주어진 패턴이 존재하지 않는 행을 인쇄하고 싶을 수 있습니다. -v 옵션을 사용하면 이를 달성할 수 있습니다.
egrep -v we sample.txt

여기서는 명령이 we라는 텍스트를 포함하지 않는 모든 줄을 인쇄하는 것을 볼 수 있습니다.
9. 패턴의 라인 번호를 찾는 방법
명령의 -n 옵션을 사용하여 줄 번호 매기기를 활성화할 수 있습니다. 그러면 패턴 일치가 성공할 때 출력에 줄 번호가 표시됩니다. 이 간단한 트릭은 출력을 더욱 의미있게 만듭니다.
egrep -n professionals sample.txt

위 출력에서 5번째 줄에 professionals라는 단어가 있는 것을 볼 수 있습니다.
10. 자동 모드에서 패턴 매칭을 수행하는 방법
자동 모드에서 egrep 명령은 일치하는 패턴을 인쇄하지 않습니다. 따라서 명령의 반환 값을 사용하여 패턴 일치 성공 여부를 식별해야 합니다.
명령의 -q 옵션을 사용하여 자동 모드를 활성화할 수 있는데, 이는 쉘 스크립트를 작성하는 동안 유용합니다.
egrep -q professionals sample.txt
egrep -q non-existing-pattern sample.txt
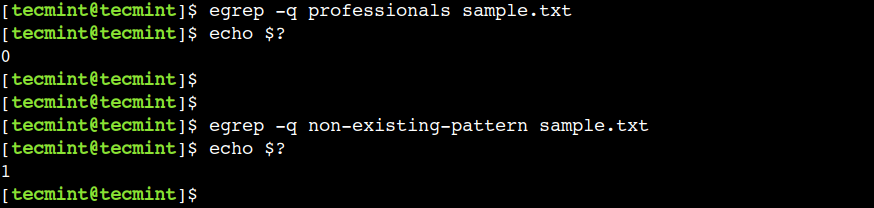
이 예에서 0 반환 값은 패턴이 있음을 나타내고 0이 아닌 값은 패턴이 없음을 나타냅니다.
11. 패턴 일치 전 라인 표시 방법
때로는 일치하는 패턴 주위에 몇 개의 선을 표시하는 것이 합리적입니다. 이러한 시나리오에서는 일치하는 패턴 앞에 N줄을 표시하는 명령의 -B 옵션을 사용할 수 있습니다.
예를 들어, 아래 명령은 패턴 일치가 성공한 줄과 그 앞의 2줄을 인쇄합니다.
egrep -B 2 -n professionals sample.txt

이 예에서는 -n 옵션을 사용하여 줄 번호를 표시했습니다.
12. 패턴 일치 후 라인을 표시하는 방법
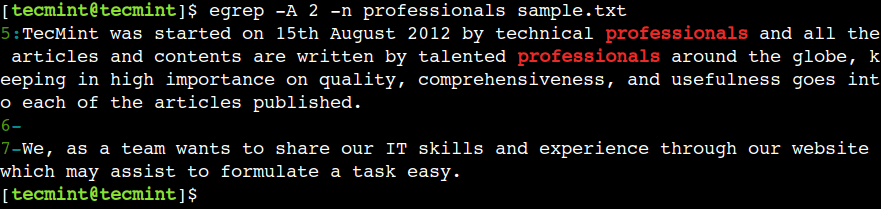
비슷한 방식으로 명령의 -A 옵션을 사용하여 패턴 일치 후 행을 표시할 수 있습니다. 예를 들어, 아래 명령은 패턴 일치가 성공한 줄과 다음 2줄을 인쇄합니다.
egrep -A 2 -n professionals sample.txt
13. 패턴 일치 주위에 선을 표시하는 방법
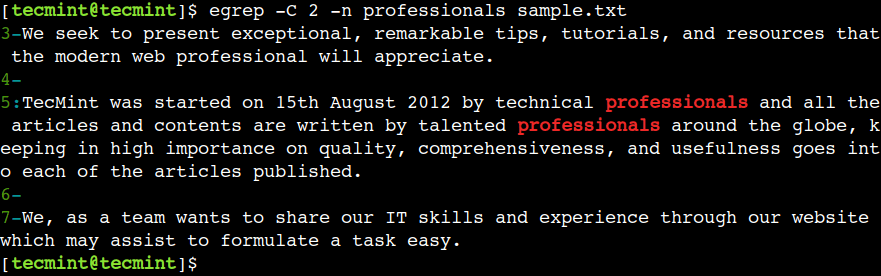
이 외에도 egrep 명령은 -A 및 -B< 옵션의 기능을 결합한 , 일치하는 패턴 전후의 행을 표시합니다.-C 옵션을 지원합니다.
egrep -C 2 -n professionals sample.txt
14. 여러 파일에서 반복적으로 패턴을 찾는 방법
이전에 설명한 대로 여러 파일에 대해 패턴 일치를 수행할 수 있습니다. 그러나 파일이 여러 하위 디렉터리에 있고 모든 파일을 명령 인수로 전달하면 상황이 까다로워집니다.
이러한 경우에는 다음 예와 같이 -r 옵션을 사용하여 재귀적인 방식으로 패턴 일치를 수행할 수 있습니다.
먼저 하위 디렉터리 2개를 만들고 여기에 sample.txt 파일을 복사합니다.
mkdir -p dir1/dir2
cp sample.txt dir1/
cp sample.txt dir1/dir2/
이제 재귀적인 방식으로 검색 작업을 수행해 보겠습니다.
egrep -r professionals dir1

위의 예에서는 dir1/dir2/sample.txt 및 dir1/sample.txt 파일에 대한 패턴 일치가 성공한 것을 확인할 수 있습니다.
15. 정규식을 사용하여 단일 문자를 일치시키는 방법
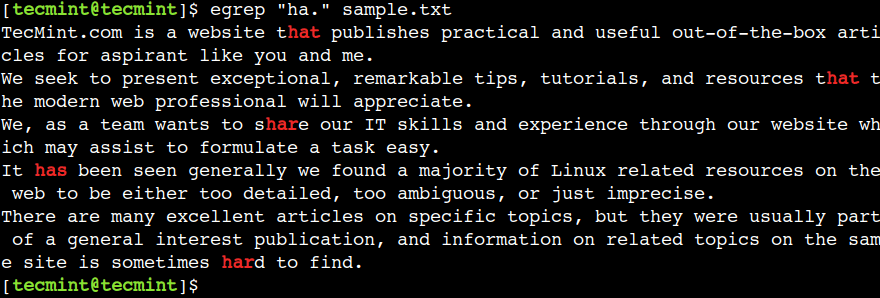
점 (.) 문자를 사용하여 줄 끝을 제외한 모든 단일 문자와 일치시킬 수 있습니다. 예를 들어, 아래 정규식은 har, hat 및 has 텍스트와 일치합니다.
egrep "ha." sample.txt
16. 0개 이상의 문자 발생을 일치시키는 방법
별표 (*)를 사용하여 이전 문자가 0개 이상 일치하도록 할 수 있습니다. 예를 들어, 아래 정규식은 we 문자열과 그 뒤에 0개 이상의 b 문자가 나오는 텍스트를 일치시킵니다.
egrep "web*" sample.txt

17. 이전 문자가 하나 이상 일치하는 방법
더하기 (+)를 사용하여 하나 이상의 이전 문자와 일치시킬 수 있습니다. 예를 들어, 아래 정규 표현식은 we 문자열과 그 뒤에 최소한 한 번 이상 등장하는 b 문자가 포함된 텍스트와 일치합니다.
egrep "web+" sample.txt
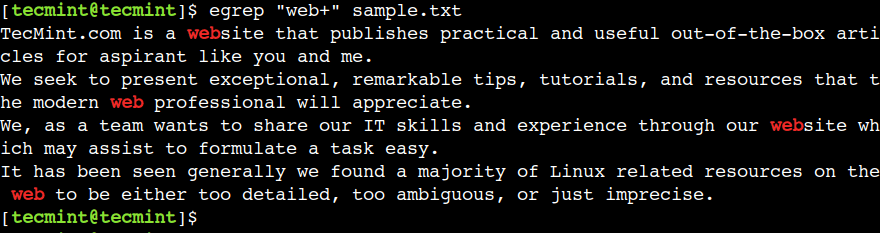
여기서는 b 문자가 없기 때문에 we 및 were 단어에 대한 패턴 일치가 성공하지 못하는 것을 볼 수 있습니다.
18. 줄의 시작을 맞추는 방법
캐럿 (^)을 사용하여 줄의 시작을 나타낼 수 있습니다. 예를 들어, 아래 정규식은 We라는 텍스트로 시작하는 줄을 인쇄합니다.
egrep "^We" sample.txt

19. 줄 끝을 맞추는 방법
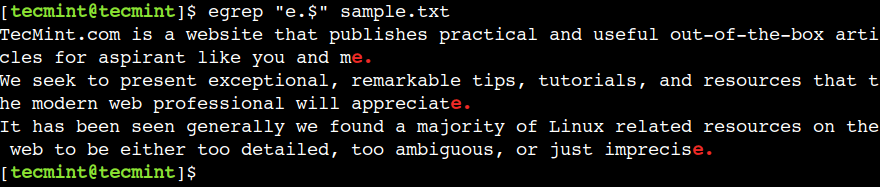
달러 ($)를 사용하여 줄의 끝을 나타낼 수 있습니다. 예를 들어, 아래 정규식은 e. 텍스트로 끝나는 줄을 인쇄합니다.
egrep "e.$" sample.txt
20. 파일에서 빈 줄을 제거하는 방법
캐럿 (^) 바로 뒤에 달러 ($)를 사용하여 빈 줄을 나타낼 수 있습니다. 빈 줄을 제거하기 위해 정규식에서 이것을 사용해 보겠습니다:
egrep -n -v "^$" sample.txt
![]()
위 출력에서 라인 번호 2, 4, 6, 8, 10은 비어 있으므로 표시되지 않는 것을 볼 수 있습니다.
결론
이 기사에서는 egrep 명령의 몇 가지 유용한 예를 논의했습니다. 생산성을 향상시키기 위해 일상 생활에서 이러한 예를 사용할 수 있습니다.
Linux의 egrep 명령에 대한 다른 최고의 예를 알고 계십니까? 아래 댓글로 여러분의 의견을 알려주세요.